
В этой статье рассмотрим особенности совместного использования Apache Kafka и Spark Streaming для обработки финансовых транзакций в режиме онлайн. Читайте далее про типовые кейсы практического применения конвейера аналитики больших данных на базе Kafka и Spark, а также проблемы или технологические особенности такой Big Data системы и пути обхода этих ограничений.
Примеры транзакционной обработки Big Data в реальном времени
Большинство финансовых компаний, интернет-магазинов, процессинговых центров и банков используют типичный стек технологий Big Data для обработки больших объемов данных, как только они были сгенерированы, то есть в реальном времени. Обычно к таким приложениям потоковой аналитики больших данных относятся их агрегация из разных источников, преобразование, обогащение и доставка в конечное местоположение, например, BI-дэшборд для принятия управленческих решений. Сюда же относится обработка финансовых транзакций также возможна, которая должна быть надежной и максимально оперативной. Для такого случая отлично подходит комбинация Apache Kafka + Spark Streaming, об интеграции которых мы рассказывали здесь.
Сам конвейер обработки платежей на базе этих технологий Big Data работает следующим образом [1]:
- Единой точкой входа в систему является API платежного шлюза (Payment gateway), через который приходят все входящие платежи;
- API платежного шлюза обрабатывает запросы с помощью RESTful-сервиса Kafka Proxy REST API, чтобы записать эти данные транзакций в топиках Apache Kafka;
- Записи о транзакциях непрерывно передаются в потоковом режиме и обрабатываются Spark-приложением.
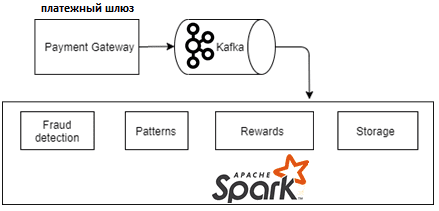
Поскольку Apache Spark включает библиотеку алгоритмов машинного обучения, здесь возможна сложная аналитики больших данных, таких как, обнаружение мошенничества (Fraud detection) или обогащение данных. Например, для процессинговых центров актуален бизнес-сценарий автоматического начисление платы за каждую транзакцию в зависимости от ее суммы и географического положения участников (продавец, покупатель). А для интернет-магазинов интересен расчет вознаграждений, скидок, бонусов и кэшбэка. После обогащения данных можно сохранить все транзакции в Hive-таблицах, например, чтобы проанализировать структуру покупок и определить для каждого покупателя любимую категорию товаров, лимиты расходов, тенденции продаж в разных странах и регионах, а также время, проведенное каждым клиентом на сайтах e-commerce.
В результате такого анализа процессинговый центр и интернет-магазин могут повысить эффективность своих рекламных кампаний, формируя персональное маркетинговое предложение для каждого клиента согласно его интересам. Также возможна организация различных партнерских программ, таких как скидки на использование определенных кредитных карт или платежных шлюзов [1]. Все подобные варианты использования Apache Kafka + Spark Streaming вполне заманчивы и понятны с точки зрения бизнеса, однако, при их технической реализации можно столкнуться с рядом особенностей этих технологий Big Data, о чем мы поговорим далее.
3 проблемы совместного использования Apache Kafka и Spark Streaming для обработки транзакций и способы их решения
При реализации вышеописанных кейсов стоит помнить о следующих особенностях Apache Kafka и Spark Streaming в рамках единого конвейера аналитики больших данных в реальном времени:
- При том, что Spark позиционируется как технология потоковой обработки больших данных, в действительности этот фреймворк использует микро-пакетный подход. Библиотека Spark Structured Streaming позволяет точнее приблизиться к real time режиму, предоставляя гибкие API таких структур данных, как DataFrame и DataSet, а также семантику строго-однократной доставки сообщений (exactly-once), чтобы гарантировать отсутствие дублей и пропусков. Подробнее об этом мы рассказывали здесь. Обратной стороной этих достоинств является замедление Spark-конвейера обработки данных и снижение пропускной способности всей Big Data системы из-за увеличения объема файлов контрольных точек, обеспечивающих отказоустойчивость. Решить эти проблемы можно через очистку компактных файлов исходных и целевых метаданных с последующим перезапуском заданий Spark Structured Streaming, например, как это было сделано в этом кейсе.
- Время, когда событие действительно произошло в реальном мире, может не совпадать с моментом его поступления в аналитический конвейер Kafka-Spark. Справиться с этим поможет CDC-подход к отслеживанию измененных данных (Сhange Data Capture), основанный на идентификации, регистрации и доставке изменений в источниках во внешние системы. Технически это реализуется с помощью табличных триггеров, отметок времени или номеров версий в строках таблиц СУБД, сканирования лог-файлов или обработки событий. Как реализовать CDC в реальном времени с большими объемами данных, мы рассматривали на примере распределенной репликации таблиц из базы головного офиса во множество филиальных СУБД с помощью Apache Kafka и Debezium. В случае транзакционной обработки CDC позволяет получить изменения оперативно и отправить их в аналитический Big Data конвейер почти с нулевой задержкой времени. Это также снижает накладные расходы на вычисления и требования к пропускной способности сети за счет сокращения объема информации. CDC отлично подходит для ETL-процессов корпоративных озер и хранилищ данных, ускоряя весь аналитический конвейер, в т.ч. с применением алгоритмов машинного обучения [2]. Подробнее о лучших практиках и реальных кейсах применения CDC-подхода с Apache Kafka и Spark Structured Streaming мы поговорим в следующей статье.
- В рамках транзакционного конвейера Кафка-Спарк нельзя просто взять и перезапустить задание Spark Structured Streaming с существующей контрольной точки (checkpoint) – понадобится обеспечить плавное и последовательное хранение смещений Kafka по определенным меткам времени (timestamp). Для этого можно считать последнее смещение контрольной точки из хранилища (обычно Hadoop HDFS), получить данные о минимальном смещении, отметка времени которого больше, чем нужный timestamp с помощью метода consumer.offsets_for_times() библиотеки Kafka-Python, или использовать встроенную реализацию startOffsetsByTimestamp в Apache Spark 3.0, которая устанавливает временную метку в миллисекундах для каждого раздела топика Кафка [3]. Подробнее обо всех этих способах читайте в нашей отдельной статье.
Освоить практику построения эффективных конвейеров аналитики больших данных с Apache Kafka и Spark вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
Источники
- https://medium.com/@rushi.pradhan_17089/kafka-and-spark-usage-in-transaction-processing-3f4c80529df1
- https://www.eckerson.com/articles/best-practices-for-real-time-data-pipelines-with-change-data-capture-and-spark
- https://medium.com/@ZeevFeldbeine/how-to-start-spark-structured-streaming-by-a-specific-kafka-timestamp-e4b0a3e9c009

