Сегодня рассмотрим проблему обработки больших сообщений в Apache Kafka Streams и способы ее решения с помощью средства сериализации и десериализации (SerDe) от немецкой ИТ-компании Bakdata. Узнайте, почему максимального лимита конфигурации max.message.bytes не хватает, зачем и как приложение Kafka Streams материализует данные, а также каким образом kafka-s3-backed-serde читает и записывает большие записи из объектных BLOB-хранилищ Amazon S3 и Azure Blob Storage.
Когда данные действительно большие: ограничения Apache Kafka
При том, что Apache Kafka относится к области Big Data, эта платформа потоковой обработки событий предназначена для множества небольших сообщений, а не огромных файлов. Однако, на практике, бывают случаи, когда размер сообщения, записываемого в топик Kafka превышает лимит, заданный в конфигурации max.message.bytes на стороне брокера. По умолчанию максимальный размер одного пакета сообщений, отправленных в топик Kafka, равен 1 МБ. Причем, этот параметр не всегда регулируется напрямую: например, в Confluent Cloud у пользователей нет возможности произвольно контролировать этот предел. Обойти это ограничение можно, разделив данные на фрагменты, чтобы каждое сообщение было меньше максимального размера, и далее обрабатывать каждый фрагмент по отдельности. Но это требует изменения базовой логики обработки, а также не применимо в некоторых сценариях. Например, сложные NLP-задачи требуют знания всего документа для анализа текстов.
Поэтому разработчики немецкой ИТ-компании Bakdata реализовали собственный сериаизатор-десериализатор (SerDe), который прозрачно хранит большие сообщения на Amazon S3 и совместим с другими подобными средствами [1]. Как это работает и каким образом приложения потоковой аналитики больших данных Kafka Streams сериализуют и десериализуют сообщения, мы рассмотрим далее.
В сердце Kafka Streams: особенности SerDe
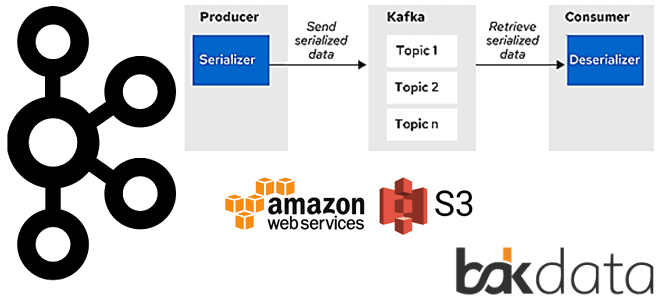
Подробно про сериализацию и десериализацию сообщений в Apache Kafka мы рассказывали здесь. Напомним, приложение Kafka Streams использует сериализатор/десериализатор для типов данных ключей и значений записи, например, java.lang.String, чтобы при необходимости материализовать данные. Операции, для которых требуется такая информация SerDes, включают: stream(), table(), to(), through(), groupByKey(), groupBy(). Настроить SerDe в Apache Kafka Streams можно следующими способами [2]:
- установка по умолчанию через экземпляр StreamsConfig;
- явное указание при вызове соответствующих методов API, отменяя значения по умолчанию.
Реализация собственного SerDe состоит из следующих шагов [2]:
- написать сериализатор для пользовательского типа данных на базе существующего класса org.apache.kafka.common.serialization.Serializer;
- написать десериализатор для пользовательского типа данных на базе класса org.apache.kafka.common.serialization.Deserializer;
- написать serde для пользовательского типа данных, через имплементацию класса org.apache.kafka.common.serialization.Serde или использование вспомогательных функций Serdes.serdeFrom (Serializer <T> , Deserializer <T>), где Т – это пользовательский тип данных.
Именно таким образом Kafka-разработчики Bakdata реализовали SerDe с открытым исходным кодом, который прозрачно обрабатывает большие сообщения, сохраняя их на Amazon S3. Это решение может использоваться с любым приложением Kafka Streams с небольшими настройками конфигурации. При этом никаких изменений в логике обработки или отправленных сообщениях не требуется. Кроме того, SerDe также может использоваться платформой Kafka Connect.
При сериализации сообщения SerDe проверяет, превышает ли размер сериализованного сообщения настраиваемый предел. Если да, то сериализованное сообщение сохраняется на Amazon S3, а уникальный URI объекта S3 отправляется в Kafka. Если размер сообщения не больше заданного лимита, оно отправляется напрямую в Kafka. При десериализации сообщения фактическое сообщение загружается из S3, если необходимо, а затем десериализуется с использованием SerDe.
Чтобы правильно десериализовать сообщения, в решение Bakdata маркируется первый байт сообщения в качестве флага, показывающего, хранится ли само сообщение в AWS S3 или нет. Таким образом, накладные расходы на использование этого SerDe составляют всего один байт плюс дополнительное время на запись большого сообщения в S3.
Ключ хранимых объектов S3 генерируется случайным образом, начинаясь с настраиваемого префикса, за которым следует имя топика, а потом сами ключи или значения. Поскольку невозможно сразу определить раздел и смещение для записи сообщения, к ключу объекта в AWS S3 добавляется случайный UUID. Таким образом, каждое сообщение имеет уникальный ключ в S3, снижая вероятность коллизии для случайных UUID. При этом нет необходимости использовать данный SerDe для ключей, т.к. их размер намного меньше, чем размер значений в сообщениях.
Большие сообщения, хранящиеся на S3, не удаляются автоматически. Хотя в Kafka данные обычно хранятся в течение ограниченного периода времени. AWS S3 предлагает аналогичную концепцию Object Expiration, которая позволяет сохранять для сообщений в S3, такие же сроки хранения, что и для тех, которые хранятся в топиках Kafka [1].
Конфигурации и ограничения kafka-s3-backed-serde
Доступный для свободного скачивания на Github инструмент SerDe от BakData предлагает следующие конфигурации для настройки сериализации и десериализации больших сообщений в Apache Kafka с поддержкой AWS S3 [1]:
- key.serde – главный класс SerDe для настройки использования, значение по умолчанию org.apache.kafka.common.serialization.Serdes$ByteArraySerde;
- value.serde — значение, используемое классом SerDe, значение по умолчанию org.apache.kafka.common.serialization.Serdes$ByteArraySerde;
- base.path — базовый путь для хранения данных, включая сегмент и префикс, например, s3://my-bucket/my/prefix/;
- max.byte.size — максимальный размер сериализованного сообщения в байтах до того, как оно будет сохранено в S3, размер по умолчанию равен 1000000 байт;
- access.key — ключ доступа AWS для подключения к S3. Не задается, если используется цепочка провайдеров учетных данных AWS.
- secret.key — секретный ключ AWS для подключения к S3. Не задается, если используется цепочка провайдеров учетных данных AWS.
- s3backed.region – используемый регион AWS S3, настраивается вместе с endpoint и не задается, если используется регион S3 по умолчанию.
- s3backed.endpoint – конечная точка для подключения к AWS S3, настраивается вместе с region и не задается, если используется endpoint S3 по умолчанию.
- path.style.access – разрешение доступа в стиле пути для клиента S3.
Другие конфигурации приведены в описании решения на Github [3].
Стоит отметить несколько ограничений этого решения. Поскольку SerDe не может определить, действительно ли сериализованное сообщение было отправлено и зафиксировано в Kafka, есть риск, что в S3 будут храниться сообщения, не связанные с каким-либо зафиксированным сообщением. Это приводит к потере некоторого объема в облачном объектном хранилище, но никак не влияет на корректность SerDe.
Кроме того, сообщения, сериализованные с помощью этого SerDe, не могут быть обработаны с помощью Confluent KSQL из-за отсутствия в этой среде пользовательских типов данных.
Наконец, поскольку хранение сообщений в S3 влечет некоторые накладные расходы, SerDe лучше всего использовать с данными, содержащими много небольших записей, чтобы их можно было напрямую отправить в Kafka, и ограниченным количеством больших сообщений (> 1 МБ). И, хотя представленный SerDe может обрабатывать данные, превышающие установленные пределы, все же следует оценить, можно ли уменьшить размер сообщений или поискать альтернативу этой платформе потоковой обработки событий. А о том, как связана сериализация и десериализация данных с попытками повторной обработки сообщений, читайте в нашей новой статье. Об особенностях соединений таблиц по внешнему ключу в новом релизе ksqlDB мы рассказываем в этом материале. А про то, как дата-инженеры Tesla решали проблему обработки больших сообщений в своей IoT-инфраструктуре, вы узнаете здесь.
Освойте администрирование и эксплуатацию Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

