
В этой статье продолжим разговор про Apache Kudu и рассмотрим, как эта NoSQL-СУБД используется с Hadoop и Cloudera Impala, чем она полезна в организации озера данных (Data Lake) и почему Куду не заменяет, а успешно дополняет HDFS и HBase для эффективной работы с большими данными (Big Data).
Apache Kudu в Data Lake для быстрой аналитики Big Data
Классическая архитектура Data Lake, ориентированная на пакетную обработку, когда данные обновляются несколько раз в день, не совсем отвечает требованиям современного бизнеса. Многие системы аналитики больших данных с функциями предупреждающих оповещений, обнаружения аномалий и информирования в реальном времени основаны на потоковом режиме работы с Big Data. Более продвинутый подход к построению таких систем на базе лямбда-архитектуры предполагает использование Apache HBase для хранения «быстрых» данных и HDFS в качестве хранилища для исторических «медленных» данных. Напомним, HBase отлично подходит для случайного поиска и быстрых операций вставки, обновления и удаления. А инструменты класса SQL-on-Hadoop, такие как Apache Hive или Cloudera Impala, позволяют работать с данными в HBase и HDFS через SQL-запросы. Тем не менее, на практике часто возникает задача одновременной обработки быстрых и медленных данных в Apache Hadoop. Именно здесь на арену выходит Apache Kudu [1].
Например, для рабочих нагрузок, связанных с изменчивостью и аналитикой в реальном времени, можно использовать Apache Kudu, а для гибкой масштабируемости при низкой стоимости хранения Big Data – HDFS. Если данных не слишком много, и они постоянно меняются, например, таблицы измерений для BI-систем, их можно хранить в Kudu. Впрочем, там эе можно размещать и большие таблицы, когда они укладываются в пределы масштабирования Apache Kudu. А если данных слишком много, они ориентированы на пакетную обработку и вряд ли изменятся, целесообразно выбрать HDFS с использованием формата Parquet [2].
Интеграция с Impala и Hive
Благодаря тесной интеграции Kudu с Impala, последнюю можно применять для поиска, вставки, обновления и удаления данных с tablet-серверов Kudu через типовой SQL-синтаксис. Также можно подключиться к данным Kudu через драйверы JDBC или ODBC, используя Impala в качестве брокера. Например, создавать новую таблицу Kudu с помощью Impala можно, объявив ее внешней или внутренней, которые отличаются следующим [3]:
- внутренняя таблица, которая управляется Impala – это наиболее распространенный способ. Его особенностью является полное удаление данных и таблицы Kudu при их удалении из Impala.
- внешняя таблица, созданная с помощью команды CREATE EXTERNAL TABLE. Impala не управляет внешней таблицей, и ее удаление не приводит к удалению таблицы из исходного местоположения, т.е. хранилища Kudu. Удаляется лишь отображение между Impala и Kudu. Этот режим используется в синтаксисе Kudu для отображения существующей таблицы в Impala.
При этом стоит помнить, что Импала инфраструктурно зависит от Apache Hive – другого популярного SQL-on-Hadoop инструмента, используя его хранилище метаданных (Hive Metastore, HMS). Оно позволяет Impala знать о доступности и структуре баз данных, автоматически сообщая изменения метаданных всем узлам Impala с помощью специализированной службы каталогов. Начиная с версии Kudu 1.10.0 и Impala 3.3.0 доступна автоматическая синхронизация каталога Куду-HMS. Поскольку между таблицами Куду и внешними таблицами может не быть однозначного отображения, автоматически синхронизируются только внутренние таблицы. Поэтому возможны следующие варианты:
- если интеграция с Hive Metastore не включена, Impala будет создавать записи метаданных в HMS от имени Kudu. При этом таблицы, создаваемые через Kudu API или другие интеграции, такие как Apache Spark и пр., НЕ будут автоматически видны в Impala. Чтобы работать с ними, следует сначала создать внешнюю таблицу через Impala и настроить ее отображение с Kudu. Например, таким образом:
CREATE EXTERNAL TABLE my_mapping_table
STORED AS KUDU
TBLPROPERTIES (
‘kudu.table_name’ = ‘my_kudu_table’
);
- при включенной интеграции с Hive Metastore, Impala следует настроить на использование того же HMS. При этом записи внутренней таблицы будут созданы автоматически в HMS, когда таблицы создаются в Kudu без Impala. Для доступа к ним через Impala следует запустить команду INVALIDATE METADATA, которая позволит Impala собирать самые последние метаданные.
4 преимущества совместного использования Kudu с HDFS через Impala на практическом примере
Пояснив основы взаимодействия Куду с HDFS и Impala, покажем, как совместное использование этих Big Data систем позволяет интегрировать достоинства каждой из них [2]:
- немедленный доступ к потоковым данным;
- возможность обновления для опоздавших или откорректированных вручную данных;
- оптимальный размер данные в HDFS повышает общую производительность системы;
- сниженная стоимость хранения данных, даже при том, что использовании облачных хранилищ данных, таких как Amazon Поскольку данные в облачном хранилище являются удаленными, запросы к ним менее производительны. Поэтому их следует использовать для хранения «холодных» данных, которые запрашиваются не часто.
В рамках этого шаблона можно с помощью Impala создавать таблицы HDFS в формате Kudu и Parquet, которые будут разделены на единицу времени в зависимости от того от частоты использования данных. На практике обычно используются ежедневные, ежемесячные или ежегодные разделы. Создается унифицированное представление, а SQL-выражение WHERE определяет границу между Куду и HDFS, чтобы перемещать данные между ними без использования представлений для дубликатов записей. После перемещения данных можно применить атомарный оператор ALTER VIEW для перемещения границы вперед [2].
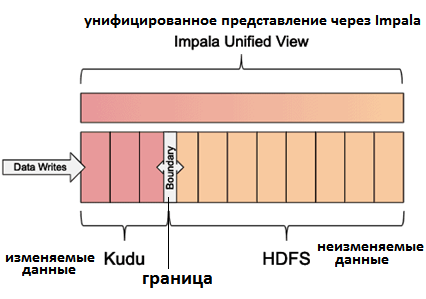
Этот шаблон лучше всего работает с последовательными данными, организованными в разделы, обеспечивая скользящее окно времени и эффективное удаление разделов [2]. В следующей статье мы продолжим разговор про Куду и рассмотрим, как эта NoSQL-СУБД используется с Apache Kafka и Spark для построения современных систем аналитики больших данных.
Еще больше подробностей про работу с большими данными с помощью Kudu и других компонентов Apache Hadoop в проектах цифровизации своего бизнеса вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Hadoop
- Администрирование кластера Hadoop
- Hadoop для инженеров данных
- Администрирование кластера Arenadata Hadoop
- Основы Arenadata Hadoop
- Интеграция Hadoop и NoSQL
Источники

