
Добавляя в наши курсы для дата-инженеров интересные кейсы, сегодня рассмотрим, как реализовать Лямбда-архитектуру для комплексной аналитики больших данных с помощью Apache Flink, Kafka и Cassandra на примере системы интернета вещей. Объединение пакетной и потоковой обработки данных средствами Flink API и библиотек этого фреймворка.
Постановка задачи на примере IoT-системы
Несмотря на разделение технологий обработки Big Data на пакетную и потоковую парадигму, тенденция к их совместному использованию и объединению в рамках одного решения становится все более четкой. Современному бизнесу нужен потоковый сбор и аналитика больших данных в режиме реального времени вместе с классическими пакетными заданиями. При этом потоковые и пакетные данные должны быть объединены перед тем, как их можно будет визуализировать и обрабатывать как объединенный набор данных. Именно эту идею реализует последняя версия вычислительного фреймворка Apache Flink, о чем мы писали здесь и здесь.
Чтобы продемонстрировать, как это работает, рассмотрим пример системы интернета вещей (Internet Of Things, IoT) по анализу данных о событиях станции измерения воздуха с ежечасным измерением набора показателей с девяти датчиков: содержание различных веществ, дата, время, температура и влажность.
Предположим, измерительная станция как IoT-устройство каждый час публикует «горячие» данные в топики Apache Kafka, где они хранятся в течение определенного периода времени, а затем удаляются. Чтобы не потерять эти исторические данные, они регулярно сохраняются в постоянной базе для дальнейшей обработки данных в любое время. Таким образом, необходимо анализировать «горячие» данные в реальном времени из Kafka и исторические данным из СУБД, т.е. запрашивать две системы с разными методами доступа. Это неудобно, плохо масштабируется и создает сложности в обслуживании.
Поэтому возникает потребность в комбинированном представлении данных из множества источников с единой точкой доступа, независимо от их схем, типов, представлений, качества и технологий обработки. При этом желательно сократить долю рутинной работы за счет автоматической очистки сырых данных. Как реализовать эти требования на уровне архитектуры данных, рассмотрим далее.
Гибридная архитектура для пакетной и потоковой обработки с Apache Flink
Идея лямбда-архитектуры впервые была представлена Натаном Марцем более 10 лет назад, в 2011 году. Lambda-архитектура содержит три уровня:
- пакетный (batch) обрабатывает все пакетные данные из баз или озер данных
- уровень скорости (speed) обрабатывает все потоковые данные в режиме реального времени, делая новые данные доступными с минимальной задержкой;
- уровень обслуживания (serving) отвечает за слияние очищенных данных с двух других уровней и предоставление их приложениям.
Ранее приходилось разрабатывать отдельное приложение для загрузки данных с пакетного и скоростного уровней, чтобы объединить их в стандартизированной форме на уровне обслуживания. С Flink такая стандартизация уже реализуется на уровнях скорости и пакетной обработки.
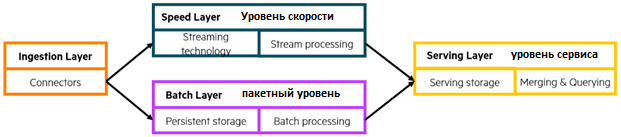
Инструментально воплотить архитектуру Lambda можно с помощью приложений Apache Flink, которые используют единый API для потоковой и пакетной обработки. Готовые коннекторы Flink позволяют связать его с другими системами. Например, чтобы получить сообщения из топика Kafka в режиме реального времени или считать исторические данные через JDBC-подключение из базы данных. Задания Flink для слоя скорости и слоя пакетной обработки отличаются только в отношении приема данных, а части обработки и вывода полностью идентичны для одного варианта использования. Flink может выводить данные в различные системы-приемники, например, NoSQL-СУБД Cassandra, которая оптимизирована для высоких рабочих нагрузок. В этом случае Cassandra будет выполнять роль сервисного уровня лямбда-архитектуры данных.
Источником потоковых данных будет Apache Kafka, а пакетных – объектно-реляционная СУБД PostgreSQL. Лямбда-архитектура системы подготовки данных для конечного использования (визуализации и BI-приложений) реализована с помощью пакетных и потоковых заданий Apache Flink и NoSQL-СУБД Cassandra.
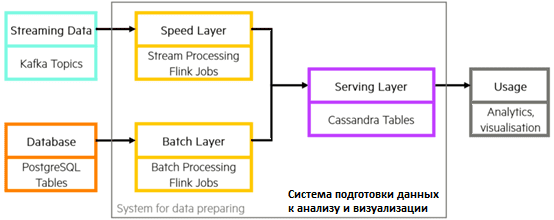
С Flink можно использовать один и тот же код для обработки пакетных и потоковых данных, поскольку фреймворк рассматривает пакеты как ограниченные потоки. Это уникальное преимущество Flink по сравнению с Apache Spark или Storm. Также Flink дает большую гибкость для сложных преобразований, позволяя писать код на Java, Python и SQL. Apache Flink состоит из нескольких компонентов, каждый из которых содержит определенные функции для различных структур данных (поток данных или таблица) и сценариев использования:
- обработка сложных событий (Complex Event Processing, CEP) – CEP-библиотека предоставляет API для указания шаблонов событий в виде регулярных выражений или конечных автоматов. Благодаря интеграции библиотеки CEP с API Flink DataStream шаблоны можно распространять на потоки данных. Эта библиотека часто применяется для таких приложений, как обнаружение сетевых вторжений, мониторинг бизнес-процессов и обнаружение мошенничества.
- DataSet API – основной программный интерфейс Flink для приложений пакетной обработки. Его примитивы включают сопоставление, сокращение, соединения, совместную группировку и итерации. Все операции поддерживаются алгоритмами и структурами данных, которые работают с сериализованными данными в памяти и перебрасываются на диск при превышении лимита. Алгоритмы обработки данных Flink DataSet API подобны традиционным операторами СУБД, такими как гибридное хэш-соединение или внешняя сортировка слиянием.
- Gelly – библиотека для масштабируемой обработки и анализа графов. Gelly реализована поверх DataSet API и интегрирована с ним. Gelly включает встроенные алгоритмы, такие как распространение меток, перечисление треугольников и ранжирование страниц, а также предоставляет Graph API, упрощающий реализацию пользовательских графовых алгоритмов.
Таким образом, Flink предлагает несколько библиотек для типовых сценариев обработки данных. Библиотеки встроены в API и не являются полностью автономными, а могут интегрироваться друг с другом и использоваться совместно. Чтобы показать, как это работает, продолжим разбор примера с IoT-системой.
Конвейеры обработки горячих и исторических данных
Чтобы подготовить и объединить потоковые и исторические данные для конечной аналитики и визуализации, построим два конвейера: для слоя скорости и пакетного слоя.
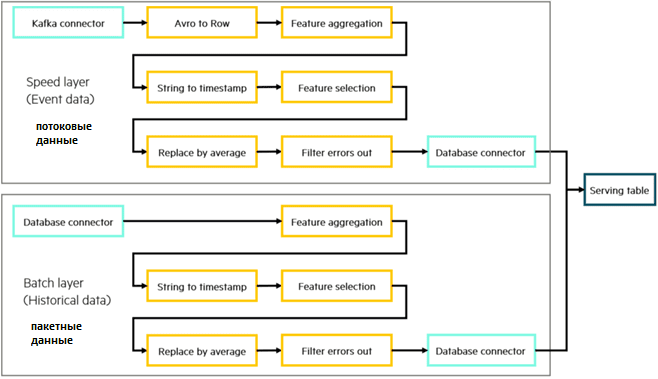
Для получения потоковых данных из Apache Kafka заданию Flink необходим соответствующий коннектор. Пусть сообщения в топиках Kafka определяются через схемы Apache Avro. Чтобы установить потребитель Kafka Consumer в задании Flink для уровня скорости, следует указать имя топика, адрес брокера и некоторые свойства подключения: URL-адрес реестра схемы и пр. Java-код потребителя и продюсера выделен в класс KafkaConnection:
public class KafkaConnection {
public static <avroSchema> FlinkKafkaConsumer010
getKafkaConsumer(Class avroSchemaClass, String inTopic, String
schemaRegistryUrl, Properties properties) {
FlinkKafkaConsumer010<avroSchema> kafkaConsumer = new
FlinkKafkaConsumer010<avroSchema>(
inTopic,
(DeserializationSchema<avroSchema>)
ConfluentRegistryAvroDeserializationSchema.forSpecific(
avroSchemaClass, schemaRegistryUrl),
properties);
kafkaConsumer.setStartFromLatest();
return kafkaConsumer;
}
}
Потребитель Kafka отправляет собранные сообщения со Avro-схемой AirQuality_value в поток данных и создает источник для потока данных в задании Flink:
FlinkKafkaConsumer010 kafkaConsumer = KafkaConnection.getKafkaConsumer(AirQuality_value.class, inTopic, schemaRegistryUrl, $properties); DataStream<AirQuality_value> inputStream = environment.addSource(kafkaConsumer);
Для чтения данных из PostgreSQL нужен JDBC-коннектор. Поэтому используется JdbcInputFormatBuilder пакета JDBC-коннектора Flink, куда передаются необходимые параметры, чтобы создать поток данных со схемой Row:
JdbcInputFormat.JdbcInputFormatBuilder inputBuilder = JDBCConnection.getSource($fieldTypes, $driverName, $dbURL, $sourceDB, $selectQuery, $dbUser, $dbPassword);DataStream<Row> inputStream = environment.createInput(inputBuilder.finish());
Прежде чем преобразовать данные в обоих слоях, нужно перевести данные в слое скорости из схемы Avro в более общую схему Row, чтобы они имели одинаковый внутренний формат. Для этого можно использовать модульные преобразователи, каждый из которых выполняет определенную операцию. Например, фильтрация сообщений из потока, изменение типов данных или их значений, преобразование атрибутов, удаление дублей. Объединив эти операции, можно построить мощные конвейеры преобразования. После этого останется записать данные в сервисный слой – обслуживающий уровень, который объединяет потоковые и пакетные данные одновременно путем записи их в одну таблицу Cassandra. Для этого можно использовать приемник JDBC или Sink-коннектор:
CassandraSink.addSink(outputStream)
.setClusterBuilder(
new ClusterBuilder() {
@Override
public Cluster buildCluster(Cluster.Builder builder) {
Cluster cluster = null;
try {
cluster = builder.addContactPoint(cassandraURL)
.withPort(cassandaPort)
.withCredentials(
cassandraUser,
cassandraPassword)
.build();
} catch (Exception e) {
e.printStackTrace();
}
return cluster;
}
}
)
.setQuery(insertQuery)
.build();
InsertQuery — это SQL-запрос вставки, который обеспечивает согласованность данных. Пакетный уровень записывает только исторические данные, а уровень скорости работает с ними некоторое время назад, когда они были текущими. Поэтому пакетный уровень переопределяет данные из уровня скорости, поскольку он более точен и заслуживает доверия. Следует убедиться, что уровень скорости не вставляет никаких данных с существующими первичными ключами, а пакетный уровень имеет возможность перезаписывать существующие строки с тем же первичным ключом. Этого можно добиться, настроив ограничение первичного ключа в таблице и определив действие при нарушении ограничения для каждого задания. Таким образом, нужна только одна стандартная таблица и не требуется отдельного сервиса для слияния данных: они уже упорядочены по первичным ключам, а конфликтов и дубликатов нет. Все внешние службы, которым нужны предварительно обработанные данные, могут получить доступ к СУБД Cassandra с помощью классических методов, используя коннекторы, REST API и пр.
Узнайте больше про администрирование и эксплуатацию Apache Flink и других компонентов экосистемы Hadoop с NoSQL-хранилищами для разработки распределенных приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Hadoop для инженеров данных
- Интеграция Hadoop и NoSQL
- Apache Kafka для разработчиков
Источники

