В этой статье для обучения дата-инженеров, аналитиков данных и разработчиков распределенных приложений рассмотрим один из методов оптимизации SQL-запросов в Apache Hive. Что такое оператор MapJoin, в каких условиях и как он работает, чем выгоден для HiveQL-запросов и почему при его выполнении с движком Tez может возникнуть нехватка памяти.
Что такое Map Join в Apache Hive
Apache Hive – это популярное NoSQL-хранилище, которое реализует возможность обращения к данным в Hadoop HDFS как к SQL-таблицам. Оно поддерживает множество методов оптимизации SQL-запросов, одним из которых является MapJoin для операции соединения таблиц. К примеру, нужно соединить большие таблицы с небольшими справочниками. В этом MapReduce-сценарии Reducer должен выполнять намного больше работы по сравнению с Mapper, включая перетасовку и сортировку данных, что отнимает много времени. Здесь пригодится MapJoin, когда вся работа выполняется на этапе Map, без шага Reduce. Shuffle-операции и сортировка не нужны, а выход Mapper’а является окончательным.
Однако, это можно использовать только для соединения на таблиц, одна из которых является небольшой, а другая – наоборот, очень объемной. Размер маленькой таблицы устанавливается Hive через свойство hive.Mapjoin.smalltable.filsize. Если файл таблицы весит меньше значения в МБ, указанного в свойстве hive.Mapjoin.smalltable.filsize, то таблица считается маленькой. Иначе – наоборот, большой. По умолчанию значение свойства hive.Mapjoin.smalltable.filsize равно 25 МБ.
Итак, для соединения маленькой таблицы с большой в Apache Hive вместо нескольких MapReduce-задач можно использовать MapJoin. При этом следует загрузить небольшую таблицу в оперативную память узла. Сделать это можно двумя способами:
- Установить свойство hive.auto.convert.join в значение true и выполнить SQL-запрос:
set hive.auto.convert.join=true; select count(*) from store_sales join time_dim on (ss_sold_time_sk = t_time_sk)
- Или сразу указать оптимизатору подсказку (hint) MapJoin в SQL-запросе на выборку данных:
select /*+ MAPJOIN(time_dim) */ count(*) from store_sales join time_dim on (ss_sold_time_sk = t_time_sk)
Важно помнить, что MapJoin не поддерживает правое и полное внешнее соединения (right и full outer join). Изначально значение конфигурации hive.auto.convert.join по умолчанию было false. Начиная с Hive 0.11.0 оно было изменено на true. При этом файл hive-default.xml.template неправильно указывает значение по умолчанию как false в версия с 0.11.0 по 0.13.1.
Hadoop SQL администратор Hive
Код курса
HIVE
Ближайшая дата курса
по запросу
Продолжительность
8 ак.часов
Стоимость обучения
24 000 руб.
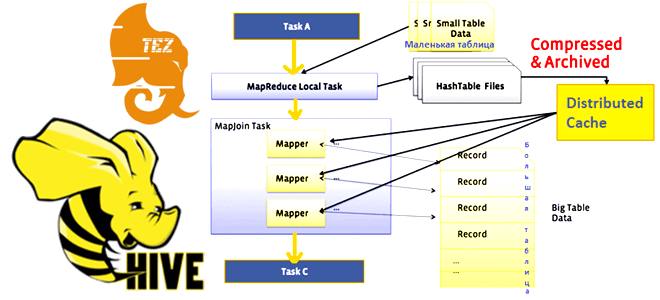
Запросы с MAPJOIN обрабатываются путем загрузки меньшей таблицы в хэш-карту в памяти и сопоставления ключей с большей таблицей по мере их прохождения. Ранее это работало так, что на локальном узле выполнялась следующая работа:
- чтение записей из источника данных через стандартное сканирование таблицы, включая фильтры и прогнозы;
- построение хэш-таблицы в памяти;
- запись хэш-таблицы на локальный диск;
- загрузка хэш-таблицу в распределенную файловую систему;
- добавление хэш-таблицы в распределенный кэш.
На этапе сопоставления хэш-таблица считывалась с локального диска из распределенного кэша в память, ключи записей сопоставлялись с хэш-таблицей, совпадения объединялись и записывались в выходной результат. Операция свертки, т.е. шаг Reduce в MapReduce-задании отсутствовал. Такая реализация MAPJOIN до Hive 0.11 имела следующие ограничения:
- оператор мог одновременно обрабатывать только один ключ — соединение нескольких таблиц было возможно, только если все они соединены по одному и тому же ключу. Обычные соединения звездообразной схемы не попадали под этот случай.
- Пользователи не всегда знают и правильно применяют подсказки, а автоматическое преобразование не всегда могло последовательно предсказать, поместится ли MAPJOIN в память или нет.
- Цепочка MAPJOIN не объединяется в одно задание только для шага сопоставления, если запрос не написан как каскадная последовательность mapjoin(table, subquery(mapjoin(table, subquery….). Автопреобразование не могло создать только Map-задание без шага Reduce.
- Хэш-таблица для MAPJOIN-оператора создавалась для каждого запуска запроса, который включает в себя загрузку всех данных на клиентский компьютер Hive, а также загрузку сгенерированных файлов хэш-таблицы. Это увеличивало время выполнения запроса из-за передачи данных по сети.
В последующих выпусках Apache Hive эти недостатки были устранены. А в альфа-релизе 4.0.0, выпущенном 30 марта 2022 года, был добавлен шаг оптимизации с целью поиска операторов Table Scan, которые уменьшают количество строк, декодируемых во время выполнения. При этом ищутся все доступные операторы MapJoin, которые могли бы использовать меньшую хэш-таблицу на стороне проверки, где находится Table Scan, чтобы отфильтровать строки, которые никогда не совпадут. Для этого информация хэш-таблицы помещается в свойства Table Scan, а затем распространяется как часть Map-задания. Если один Table Scan используется несколькими операторами (shared-word), правило не применяется. Это правило можно расширить для поддержки выражений статического фильтра в простых SQL-запроса типа select * from sales where sold_state = ‘PR’. Эта оптимизация нацелена главным образом на исполняющий движок Tez, работающий на LLAP (Live Long And Process) — механизм выполнения, который поддерживает длительные процессы, используя одни и те же ресурсы для кэширования и обработки. Альтернативой Tez для выполнения SQL-запросов в Apache Hive является вычислительный движок Spark, о чем мы писали здесь. Необходимость оптимизации для Tez была также обусловлена проблемой нехватки памяти при выполнении MapJoin-операций, что мы рассмотрим далее.
OOM и другие тонкости MapJoin
Проблема нехватки памяти (OOM, Out Of Memory) при соединении таблиц с помощью MapJoin возникала, если параметр hive.auto.convert.join.noconditionaltask был установлен в значение true. Если сумма размеров соединяемых таблиц была меньше, чем noconditionaltask.size, план генерировал Map-соединение, не принимая во внимание накладные расходы на запись данных в пространстве кучи Java. При использовании движка Tez в Hive пространство кучи на самом деле принадлежит контейнеру Tez, а контейнер памяти для кучи определяют параметры hive.tez.container.size и hive.tez.java.opts. OOM-ошибка не означает, что размер контейнера слишком мал, а показывает, что размера кучи Java (hive.tez.java.opts) недостаточно. Параметр hive.tez.java.opts должен составлять около 80% от hive.tez.container.size, и не в коем случае не превышать общее значение Tez-контейнера.
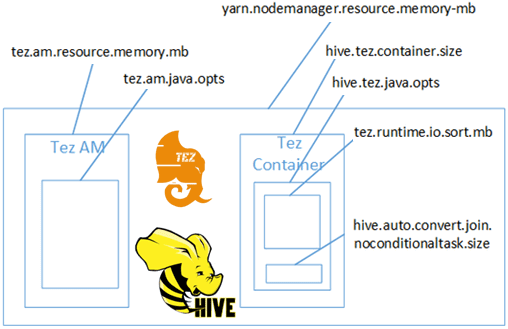
Чтобы явно выполнить MapJoin, необходимо сперва установить следующие свойства, которые по умолчанию имеют значение true:
set hive,auto.convert.join = false set hive.ignore.Mapjoin.hint = false
Затем явно указать подсказку в SQL-запросе, например:
select /* +MAPJOIN(o) */ c.customer_id, o.order_id from customers c join orders o on c.id = o.customer_id
В этом запросе MAPJOIN(o) – это подсказка для оптимизатора Hive, что таблица заказов (orders), отмеченная как o, является маленькой, т.е. будет загружаться в память локального узла.
Освойте практические навыки эксплуатации Apache Hive для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://newtechaudit.ru/poleznye-vozmozhnosti-hiveql/
- https://cwiki.apache.org/confluence/display/Hive/LanguageManual+JoinOptimization
- https://vaibhavvaidya1995.medium.com/map-side-join-in-hive-3f34efc0a68b
- https://docs.microsoft.com/ru-ru/azure/hdinsight/hdinsight-hadoop-hive-out-of-memory-error-oom
- https://issues.apache.org/jira/browse/HIVE-23006
- https://issues.apache.org/jira/browse/HIVE-8306

