Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут Apache Kafka, Лямбда-архитектура, контейнеризация и бессерверные вычисления.
MLOps-шаблоны внедрения ML-моделей в production
MLOps-энтузиасты выделяют следующие паттерны внедрения моделей машинного обучения в production [1]:
- Модель как услуга или сервис (Model-as-Service);
- Модель как зависимость (Model-as-Dependency);
- Предварительный расчет (Precompute);
- Модель по запросу (Model-on-Demand);
- Гибридная модель обслуживания (Hybrid Model Serving) или Федеративное обучение (Federated Learning)
|
Критерий |
ML-модель |
||
|
Обслуживание и версионирование (Service & Versioning) |
Вместе с приложением-потребителем |
Независимо от приложения-потребителя |
|
|
Доступность во время компиляции или выполнения (Compile/Runtime Availability) |
Доступна во время сборки и выполнения (Build and runtime available) |
Доступно удаленно через REST API или RPC-интерфейсы |
Доступна во время выполнения |
|
Шаблон обслуживания (Serving Pattern) |
Модель как зависимость (Model-as-Dependency) |
Модель как сервис (Model-as-Service) |
Предварительный расчет (Precompute) и Модель по запросу (Model on Demand) |
|
Гибридная модель обслуживания (Hybrid Model Serving) или Федеративное обучение (Federated Learning) |
|||
Что представляет собой каждая из вышеотмеченных моделей и как она связана с технологиями Big Data, мы рассмотрим далее.
Модель как услуга (Model-as-Service)
Это весьма распространенный шаблон для предоставления модели машинного обучения в качестве независимой услуги. Обычно это реализуется через заключение ML-модели и интерпретатора в выделенную веб-службу, к которой приложения-потребители данных запрашивают через REST API или удаленный вызов процедур (RPC, Remote Procedure Call). Такой паттерн пригоден для различных рабочих процессов машинного обучения, от пакетного прогнозирования до онлайн-обучения модели в потоковом режиме.

Модель как зависимость (Model-as-Dependency)
Это наиболее простой способ упаковать модель машинного обучения, которая рассматривается как зависимость внутри программного приложения. Например, приложение использует ML-модель как обычную зависимость от jar-файла, вызывая метод прогнозирования и передавая значения. Возвращаемое значение такого метода — некоторый прогноз, который выполняется предварительно обученной ML-моделью. Как правило, этот подход используется в задачах простого пакетного прогнозирования.
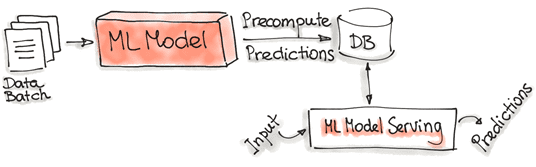
Предварительный расчет (Precompute)
В этом случае прогнозы предварительно вычисляются с использованием уже обученной ML-модели для входящего пакета данных и сохраняются в базе. Далее к этой базе идет обращение при любом входном запросе, чтобы получить результат прогнозирования. С архитектурной точки зрения это похоже на Лямбда-шаблон, когда «горячая» обработка данных в потоковом режиме совмещается с «холодной», где пакеты исторических данных подгружаются из хранилища, в качестве которого обычно выступает Data Lake на Apache Hadoop. Подробнее о том, что такое лямбда-архитектура в Big Data системах, мы рассказывали здесь.
Модель по запросу (Model-on-Demand) c Apache Kafka
Этот вариант рассматривает модель машинного обучения как зависимость, доступную во время выполнения. Однако, в отличие от шаблона «Модель как зависимость», Model-on-Demand имеет собственный цикл выпуска и публикуется независимо. Для этой реализации обычно используется брокер сообщений, например, Apache Kafka или RabbitMQ (чем они отличаются, мы писали здесь). В этом случае применяется популярный в Big Data подход потоковой обработки событий (event-stream processing), когда данные представляются в виде потока событий, объединенные в канал. Каналы событий представляют собой очереди сообщений: входную и выходную. Брокер сообщений позволяет одному процессу записывать запросы на прогнозирование во входную очередь. Обработчик событий (event processor) содержит модель, обслуживающую среду выполнения, и ML-модель. Этот процесс подключается к брокеру, считывает из очереди запросы в пакетном режиме и отправляет их ML-модели для прогнозирования. Процесс обслуживания модели запускает генерацию прогнозов для входных данных и записывает полученные прогнозы в выходную очередь. Оттуда результаты прогнозирования отправляются в сервис, который инициировал запрос.
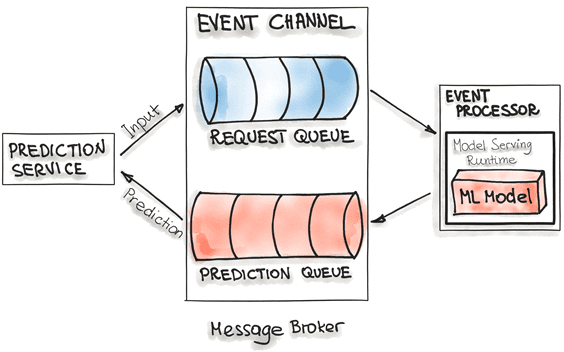
Гибридная модель обслуживания (Hybrid Model Serving)
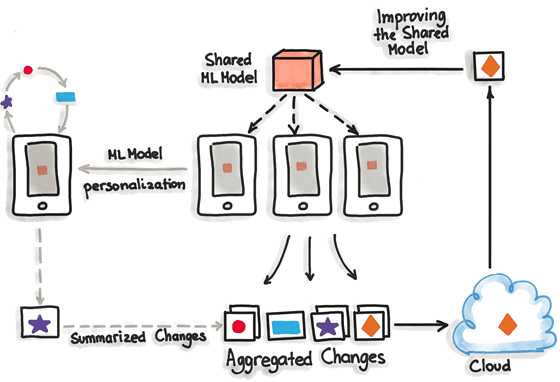
Уникальность федеративного обучения или гибридного обслуживания в том, что оно работает со множеством ML-моделей, индивидуальных для каждого пользователя в дополнение к той, которая хранится на сервере. Серверная модель обучается только один раз с реальными данными и выступает в качестве начального образца для каждого пользователя. Далее она может видоизменяться в пользовательских вариациях, даже на мобильных устройствах, параметры которых сегодня позволяют обучать собственные ML-алгоритмы. Периодически пользовательские устройства отправляют на сервер уже обученные данные своей ML-модели, корректируя серверный вариант. Оттуда эти изменения могут быть распространены на остальных пользователей, с учетом предварительной проверки и тестирования на функциональность.
Главным плюсом такого гибридного подхода является то, что обучающие и тестовые датасеты, которые носят исключительно личный характер, никогда не покидают пользовательские устройства, сохраняя при этом все доступные данные. Это позволяет обучать высокоточные ML-модели без необходимости хранить гигабайты данных в облаке. Однако, стоит помнить, что обычные алгоритмы машинного обучения ориентированы на однородные и большие датасеты, которые обрабатываются на мощном оборудовании и всегда доступны для обучения. Современные мобильные устройства пока еще менее мощные, чем специализированные Big Data кластера, а также обучающие датасеты распределены по миллионам устройств, которые не всегда доступны. С учетом этого был создан отдельный фреймворк – TensorFlow Federated, облегченная форма TensorFlow для федеративного обучения.
Как внедрить Machine Learning в production: 2 главные стратегии MLOps
С учетом вышерассмотренных паттернов эксплуатации ML-моделей, выделяют следующие стратегии их внедрения в production-системы [1]:
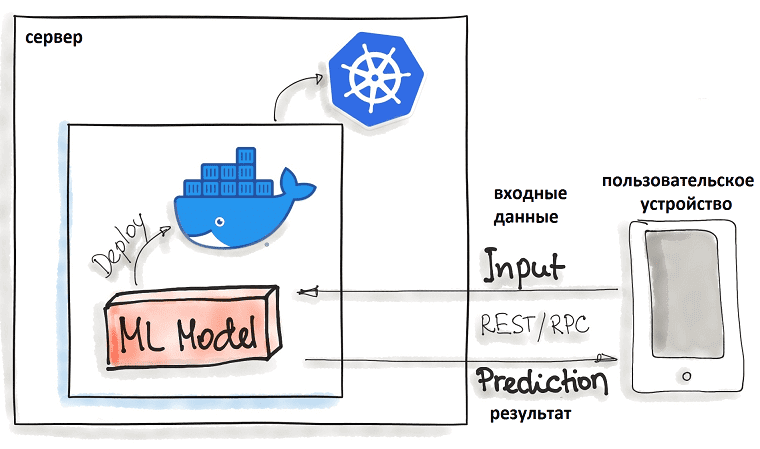
- развертывание с помощью Docker-контейнеров, что подходит для легковесных идемпотентных ML-моделей без сохранения состояния. В этом случае код модели машинного обучения заключен в Docker-контейнер, который считается наиболее распространенной технологией контейнеризации для локального, облачного или гибридного развертывания. Оркестрация таких контейнеров обычно выполняется с помощью Kubernetes или альтернатив, таких как AWS Fargate. Функциональные возможности модели Machine Learning доступны через REST API, например, в виде приложения Flask. Таким образом, здесь активно используются наиболее популярные DevOps-технологии.
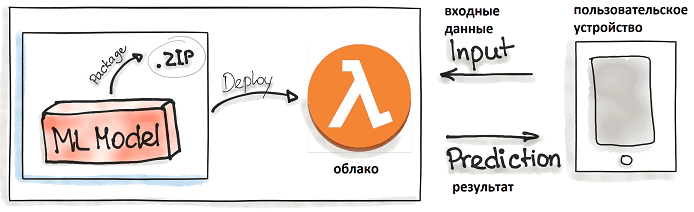
- Бессерверные вычисления (serverless), когда код приложения и зависимости упаковываются в файлы .zip с одной функцией точки входа. Затем этой функцией могут управлять основные облачные провайдеры, такие как Azure Functions, AWS Lambda или Google Cloud Functions. Однако следует обратить внимание на возможные ограничения развертываемых артефактов, в частности, их размеры. Напомним, serverless-подход реализует PaaS- или FaaS- (функция как услуга, Function as a Service) стратегию, когда облако автоматически и динамически управляет выделением вычислительных ресурсов в зависимости от пользовательской нагрузки. При этом для выполнения каждого запроса (вызова функции) создается отдельный контейнер или виртуальная машина, уничтожающиеся после выполнения. Преимуществом этого является избавление пользователей от работы по выделению и настройки серверов, в т.ч. виртуальных машин, контейнеров, баз данных, приложений, экземпляров сред выполнения. Все конфигурации и планирование вычислительных ресурсов для запуска кода по требованию или по событию скрыты от пользователей и управляются облаком. Бессерверный код может быть частью приложений, построенных на традиционной архитектуре, например, на микросервисах [2]. Обратной стороной этих достоинств являются зависимость от облачного провайдера, сложность в поиске причин случившихся ошибок из-за многослойной инкапсуляции внутреннего устройства всей системы, а также время на запуск облачной функции, которое может быть критично для бизнеса [3].
Какой выбрать паттерн эксплуатации ML-моделей и стратегию внедрения для практического использования технологий больших данных и машинного обучения в проектах цифровизации частного бизнеса или цифровой трансформации государственных и муниципальных предприятий, вы узнаете на наших специализированных курсах в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Аналитика больших данных для руководителей
- Построение эффективных конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
- Интеграция Hadoop и NoSQL
Источники
- https://ml-ops.org/content/three-levels-of-ml-software
- https://ru.wikipedia.org/wiki/Бессерверные_вычисления
- https://mkdev.me/posts/chto-takoe-serverless-arhitektura-i-v-chyom-eyo-preimuschestva