Что не так с датасетами в системах машинного обучения, с какими трудностями сталкиваются аналитики, инженеры данных и специалисты по Data Science при внедрении MLOps, почему важна согласованность различных информационных хранилищ, зачем и как внедрять оперативный мониторинг за качеством данных. Разбираем трудности разработки и поддержки Machine Learning в production.
5 проблем с данными в Machine Learning
Основными проблемами ML-систем, которые связаны с данными, можно назвать следующие:
- Недостаточно обучающих данных – для обучения ML-модели нужно огромное количество примеров для каждого случая, чтобы точно идентифицировать его в реальных условиях. Чем разнообразнее набор данных, поступающих в ML-модель, тем выше точность ее прогнозов. Поэтому обучающих данных никогда не бывает слишком много. При этом они должны быть разнообразными, чтобы избежать переобучения.
- Низкое качество данных – как обучающих, так и реальных. Чем лучше будут проанализированы обучающие данные, тем выше вероятность точных прогнозов модели Machine Learning. Аналогично, если в обучающие данные не попали новые случаи, модель не сможет обобщать результаты, и ее прогнозы будут необъективными.
- Переобучение, когда ML-модель обучается на смещенных или слишком больших объемах обучающих данных. Переобучение негативно влияет на производительность модели после развертывания. Например, при использовании нейросетей для ML-модели в задаче, которую можно решить с помощью линейной регрессии. Или если модель обучается с большими эпохами даже при высокой точности обучения, результаты не могут быть обобщены на валидационный и производственный датасеты.
- Недообучение, когда ML-модель обучается с такими данными, которые заставляют ее устанавливать неоднозначную связь между входными и выходными переменными. Это также происходит, когда алгоритм слишком прост для обучающего датасета, к примеру, линейная ML-модель на мультиколлинеарном множестве.
- Несоответствующие фичи, когда в обучающем датасете слишком много нерелевантных фичи/или чрезмерно связанных друг с другом предикторов, что называется мультиколлинеарностью, увеличивает объем признакового пространства, снижает скорость вычислений и повышает их сложность. В таких случаях система машинного обучения может не дать желаемых результатов. Поэтому этап выбора и подготовки фичей (feature engineering) чрезвычайно важен, о чем мы писали здесь.
Устранить все эти проблемы ML-систем или снизить их негативное влияние на результат обучения помогают лучшие MLOps-концепции, которая обеспечивает быстрое, непрерывное и масштабируемое производство приложений машинного обучения. MLOps определяет новый жизненный цикл ML-системы, параллельный SDLC и CI/CD, делая модель машинного обучения более эффективной, а рабочий процесс — более продуктивным. MLOps объединяет возможности аналитиков, исследователей Data Science, DevOps- и дата-инженеров, разработчиков и других ИТ-специалистов, которые работают вместе в рамках создания, развертывания и эксплуатации ML-систем. MLOps состоит из следующих компонентов, обеспечивающих максимальную производительность модели и рентабельность инвестиций:
- Обслуживание моделей и конвейерная обработка;
- Каталогизация сервисов для моделей в производстве;
- Управление версиями данных и моделей;
- Мониторинг;
- Управление инфраструктурой и ПО;
- Безопасность.
MLOps отвечает за оптимизацию и поддержание максимальной эффективности машинного обучения. Однако, практическое внедрение MLOps осложняется следующими проблемами, связанными с ограничениями реального бизнеса и производственной ИТ-инфраструктуры, которые мы рассмотрим далее.
ТОП-5 сложностей внедрения MLOps
Одна из проблем ML-систем в реальных проектах связана со снижением точности онлайн-прогнозов. Предположим, в банковской ML-системе обнаружения финансового мошенничества есть сервис, который использует модель машинного обучения для анализа кредитных заявок и принятия решения о вероятности мошенничества. Когда приходит запрос, сервис должен запросить у базы данных информацию о текущем пользователе, включая его скоринговую оценку, количество поданных заявок на кредит за последнюю неделю, средний доход и прочие фичи, важные для прогнозирования.
В рассмотренном кейсе модель машинного обучения требует знания последних фактов о пользователе, чтобы сделать правильный прогноз. Простое на первый взгляд обогащение данных поднимает несколько проблем, с которыми сталкивается дата-инженер в этом ML-проекте:
- как гарантировать минимальное время отклика от базы данных порядка пары миллисекунд, чтобы это не повлияло негативно на процесс принятия решения?
- как масштабировать базу данных, чтобы справиться с пиком нагрузки при большой генерации пользовательских событий?
- как обеспечить устойчивость всей системы, чтобы процесс прогнозирования не снижал производительность остальных частей?
При внедрении data-driven управления в корпоративные бизнес-процессы очень важны хранилища данных и возможность их оперативной интеграции. На практике многие владельцы данных хранят их в собственных локальных хранилищах, что создает трудности в согласованности информации и снижает возможность извлечения из нее ценных бизнес-инсайтов.
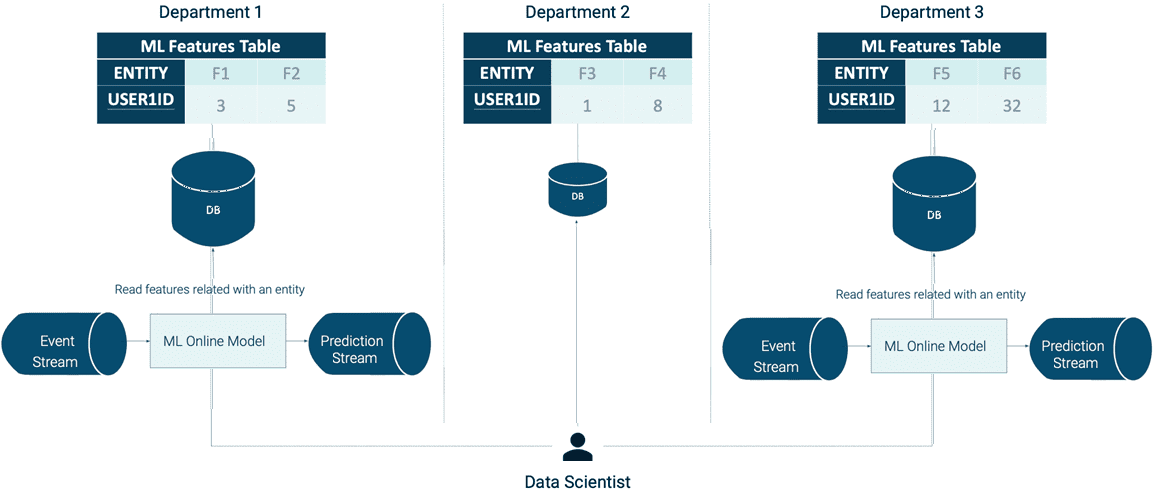
В результате такого неконсистентного хранения информации аналитик и Data Scientist сталкиваются со следующими проблемами:
- несоответствие идентификаторов между хранилищами может затруднить объединение данных из разных источников, а иногда даже сделать его невозможным;
- исследователь должен понимать структуры данных из множества разных баз и файловых хранилищ, что отнимает время от основной работы по разработке ML-моделей;
- поиск признаков определенного объекта осложняется разным временем обновления данных в различных хранилищах.
С разными хранилищами данных связана еще одна проблема внедрения MLOps – мультиоблачность. Активное использование облачных технологий, с одной стороны, снижает затраты на обеспечение ИТ-инфраструктуры, но усложняет процессы разработки и согласованности различных сервисов. К примеру, использование MySQL для реляционных данных и Redis для быстрого кэширования создает трудности в создании высококачественных ML-моделей, требуя от разработчиков понимания тонкостей различных SQL-диалектов. Управление безопасным доступом к данным в мультиоблачных средах тоже не самая тривиальная задача. Наконец, соединение данных из разных СУБД может оказаться очень сложным или даже невозможным при работе с продуктами различных провайдеров или смешивании технологий SQL и NoSQL.
Изменчивость данных со временем характерна для ML-систем, но поддается отслеживанию и контролю довольно трудно. Особенно, когда нужно вовремя отслеживать изменения в домене. Предположим, есть ML-модель целевых рекламных кампаний email-рассылок для пользователей интернет-магазина. Имеется поток событий с информацией о пользователе (индентификатор, возраст, любимый цвет) и события, связанные с ранее сделанными заказами.
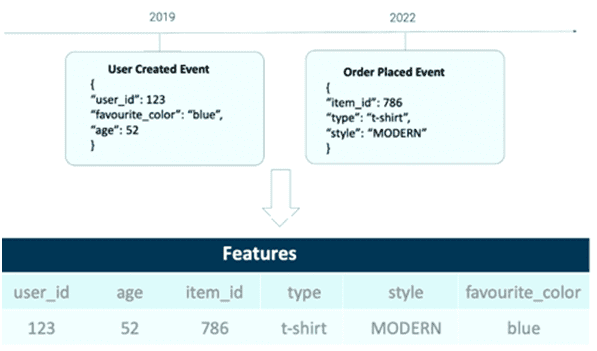
Нужно создать представление домена, чтобы объединить информацию о пользователях с их заказами. Но домен со временем меняется: требуется знать его состояние с точного момента, когда произошло каждое событие. Например, пользователю, которому в 2019 году было 52 года, в 2022 году исполнится 55 лет. При построении ML-моделей на основе прошлых данных важно помнить, что мир изменился с момента сбора этих данных:
- заранее неизвестно, являются ли обрабатываемые данные новыми или устаревшими, поэтому необходима некоторая информация TTL (Time To Live, время жизни), которая говорит о том, как долго имеющиеся данные еще являются актуальными, т.е. НЕ устаревшими;
- поскольку состояние предметной области постоянно меняется, необходим доступ к последним данным для обучения, чтобы модели могли качественно работать в производственной среде;
- важно отслеживать производительность ML-модели с течением времени, чтобы убедиться, что она по-прежнему работает хорошо. Поэтому нужно оценить модель на данных за разные периоды и проверить, постоянна ли производительность.
- объем и скорость передачи данных продолжают расти. Для внедрения MLOps нужны способы эффективного управления растущими объемами данных в больших масштабах.
Наконец, еще важной проблемой внедрения MLOps является искажение данных. Для каждой фичи, используемой для обучения моделей Machine Learning, следует записывать ожидаемый диапазон значений и распределение. Когда Data Scientist строит модель, использующую эту фичу в качестве входных данных, он также должен хранить информацию о том, насколько каждая фича влияет на выходные данные этой модели. Эта информация может быть использована для мониторинга объектов на предмет неожиданных изменений в стоимости или распределении, которые могут сделать недействительными предположения, сделанные во время моделирования.
Если значение фичи значительно меняется со временем, производительность модели может снизиться. В крайнем случае, если поврежденная ML-модель генерирует эту фичу, она перестанет работать. Поэтому на практике нужны системы контроля качества и производительности ML-моделей.
Обучающие данные необходимо отслеживать и обнаруживать изменения в них, чтобы своевременно переобучить модель и гарантировать точность прогнозов. Обнаружить ошибку и вернуть фичи к последней правильной версии поможет мониторинг данных. Таким образом, первым шагом внедрения MLOps становится разработка системы мониторинга данных, а потом уже можно разрабатывать алгоритмы и интегрировать их в производственные системы.
Как устранить вышеописанные проблемы, внедрив лучшие практики MLOps для эффективной аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники