 583
583 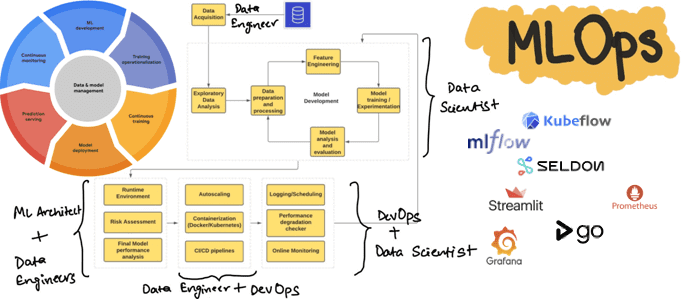
Содержание
Сегодня рассмотрим, как реализовать полноценный MLOps-цикл, используя свободные инструменты с открытым исходным кодом: MLflow, Kubeflow, Seldon, Streamlit, AirFlow, Git, Prometheus и Grafana.
Процессы жизненного цикла ML-систем
Концепция MLOps использует проверенные методы DevOps для автоматизации создания, развертывания и мониторинга конвейеров машинного обучения в производственной среде, устраняя рост технического долга в ML-проектах. По мере развития MLOps как дисциплины растет число инструментов и фреймворков с открытым исходным кодом, а также увеличивается количество проприетарных платформ. Платформы MLOps должны предоставлять основные технические возможности и инструменты, которые позволят организациям эффективно реализовывать процессы жизненного цикла ML-моделей:
- Разработка конвейера Machine Learning — организация рабочих процессов обучения и прогнозирования, включая координацию всех этапов (подготовка данных, обучение модели, оценка и пр.), а также упрощение автоматизации развертывания воспроизводимых конвейеров.
- Отслеживание экспериментов машинного обучения и метаданных для сбора информации о том, какие данные вошли в какую модель, которая привела к тому или иному результату производительности, включая параметры модели и артефакты.
- Развертывание ML-модели, чтобы упаковать и развернуть обученную модель в целевой среде обслуживания.
- Автоматизация расширяет традиционную CI/CD для поддержки непрерывного обучения в дополнение к автоматизации сборки, тестирования и выпуска конвейеров машинного обучения.
- Обслуживание ML-модели позволяет развернутой модели принимать запросы прогнозирования для логического вывода, принимая входные данные и предоставляя ответы с прогнозируемыми результатами.
- Мониторинг, чтобы отслеживать развернутую модель в рабочей среде и создавать отчеты для выявления ухудшения производительности и информирования о дальнейших действиях.
Хотя большинство инструментов с открытым исходным кодом специализируются на одной или нескольких основных функциях, например, MLflow, Kubeflow и пр., также существуют коммерческие решения, объединяющие некоторые из этих возможностей в унифицированной и управляемой платформе. Чтобы унифицировать MLOps-платформу без сильной привязки к отдельным инструментами, можно использовать принцип сквозной архитектуры, которая может быть развернута в любом кластере, совместимом с Kubernetes: локально или в облаке. Если эта архитектура соответствует шаблону микросервисов, компоненты можно развертывать по отдельности и интегрировать с помощью вызовов API. Хотя выбор MLOps-инструментов зависит от многих факторов, что мы рассматривали здесь, далее разберем пример построения MLOps-платформы и использованием популярных открытых инструментов.
MLOps-инструменты
Сервисы разработки ML-конвейеров Kubeflow и MLflow должны быть развернуты первыми, и быть подключены в рабочей области Kubeflow через URI MLflow. После развертывания GoCD может отслеживать репозиторий Github и связываться с хостами MLflow и Seldon Core для облегчения развертывания. Prometheus развертывается в кластере и настраивается с конечными точками кластера Kubernetes для мониторинга и интеграции с Grafana для предоставления собранных метрик. Streamlit находится на уровне потребления архитектуры для взаимодействия с конечными точками любых развернутых моделей.
Рабочий процесс начинается с разработки конвейера машинного обучения, который поддерживает исследование и разработку данных в рамках сервера ноутбуков Kubeflow. Это совместное, но изолированное рабочее пространство, в котором Data Scientist’ы могут работать и масштабировать эксперименты, создавая конвейеры машинного обучения с помощью Kubeflow Pipeline SDK, предметно-ориентированного языка для указания полного рабочего процесса моделирования, шагов или компонентов и того, как они взаимодействуют друг с другом.
SDK упаковывает каждый шаг, например, предварительную обработку данных, обучение и проверку модели, в виде отдельного образа Docker и будет работать в своем собственном контейнере в базовой инфраструктуре Kubernetes. Компоненты рабочего процесса модели выражаются в виде заданий, которые должны быть отправлены в конвейеры Kubeflow. Data Scientist не должен знать об оркестровке и управлении контейнерами, которые Kubeflow выполняет автоматически.
Kubeflow преобразует код в контейнер DAG, а затем позволяет AirFlow автоматически организовывать весь рабочий процесс. Kubeflow дает возможность запускать несколько модулей обучения модели параллельно. Но, хотя у Kubeflow есть пользовательский интерфейс, который показывает эксперименты и обучающие прогоны, ему не хватает сложности MLflow и способности легко сохранять данные прошлых экспериментов, что может затруднить мониторинг и воспроизводимость. MLflow намного лучше отслеживает эксперименты. Это основная мотивация для интеграции MLflow с Kubeflow.
Запуск эксперимента или обучения обычно запускает действия по отслеживанию экспериментов в виде простых вызовов API MLflow в коде конвейера. Таким образом, платформа отслеживает и сохраняет на сервере MLflow необработанные, очищенные/обработанные данные, схемы, обученные модели, гиперпараметры, результаты оценки и другие метаданные и артефакты, включая версию Python, используемую при обучении моделей. Все отслеживаемые артефакты затем отображаются через пользовательский интерфейс MLflow, где они легко доступны для проверки экспериментальных запусков.
MLflow поставляется с возможностью реестра моделей, которая позволяет легко управлять жизненным циклом ML-моделей путем хранения, управления версиями и организации моделей в промежуточные или производственные развертывания. MLflow также предлагает встроенную интеграцию с несколькими службами развертывания, включая Seldon Core. Таким образом, служба развертывания Seldon Core настроена на выбор соответствующих моделей из реестра моделей MLflow, развертывание моделей в целевой среде обслуживания и создание конечных точек для обслуживания модели в рабочей среде.
Seldon Core позволяет развертывать ML-модели в любом кластере Kubernetes как локально, так и в любом облаке. Благодаря независимость возможностей платформы от инструментария, можно заменить Seldon Core и реализовать альтернативы в облаке Azure через MLflow. Кластер логических выводов Azure Kubernetes Services (AKS) обеспечит развертывание моделей в рабочей области машинного обучения Azure без изменения каких-либо вышестоящих задач на платформе. Это позволяет развернуть модели в разных целевых средах без изменения кода, за исключением уровня развертывания. Чтобы быстро создавать веб-приложения в качестве потребляющего интерфейса, который может совершать вызовы к конечным точкам развернутой модели в обслуживающем механизме, можно использовать Python-платформу Streamlit. Она позволит обеспечить интерактивный онлайн-вывод, а также предоставляет возможность пакетного вывода для массовой оценки данных.
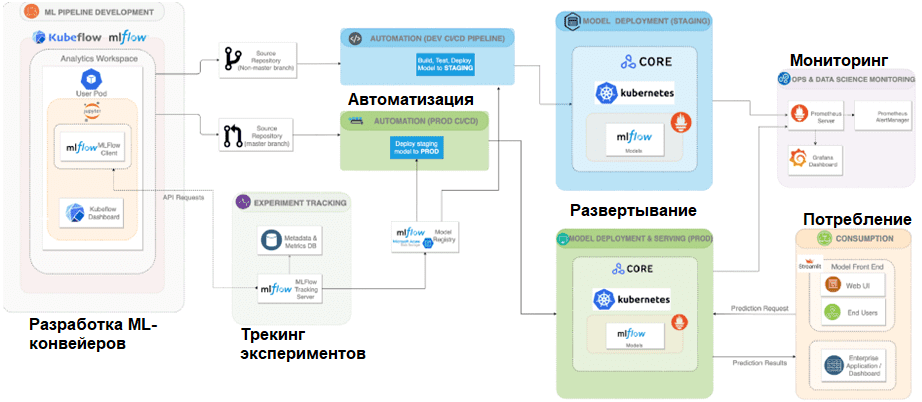
Автоматизация и обслуживание платформы
Чтобы автоматизировать этапы разработки и внедрения ML, можно использовать GoCD для развертывания конвейеров. Такая реализация CI/CD гарантирует, что можно создавать, тестировать, выпускать и запускать весь конвейер машинного обучения. Data Scientist может запустить свои конвейеры обучения и развертывания, отправив изменения в репозиторий Github, где хранится код, что автоматически запускает конвейер GoCD. Автоматизированное обучение и развертывание конвейера также обеспечивает процесс непрерывного обучения, который отличает решения машинного обучения от традиционных программных приложений, не требующих переобучения.
В качестве инструментов мониторинга можно использовать Prometheus и Grafana для отслеживания метрик в реальном времени для визуализации на информационной панели. Это позволяет поддерживать непрерывный мониторинг работоспособности работающих моделей, а также базовых инфраструктур. Prometheus и Grafana собирают операционные метрики, например, скорость запросов и задержку, и метрики качества модели (дрейф данных, дрейф модели, обнаружение выбросов), а также пользовательские метрики, относящиеся к конкретным вариантам использования, реализованным на платформе. В дополнение к отслеживанию и визуализации можно также настроить механизм оповещения и эскалации, чтобы обеспечить функциональность для уведомления службы поддержки по телефону при обнаружении отклонений в данных или в ML-модели. Имея работающий сервер CI/CD, можно инициировать автоматическое переобучение и развертывание для определенных моделей на основе пороговых значений предупреждений.
В заключение отметим, что MLOps требует изменения культуры, включая глубокое участие и согласование между командами по вопросам управления версиями кода, частоте развертывания, сквозному тестированию и управлению. Кроме того, использование открытых и облачных собственных или управляемых сервисов потребует обширных знаний об этих инструментах и фреймворках, а также способности поддерживать и отлаживать их в большом масштабе. С какими сложностями можно столкнуться при внедрении MLOps-практик в системы глубокого обучения, читайте в нашей новой статье. А про автоматизацию развертывания ML-моделей в лучших DevOps-практиках с помощью GitLab CI/CD, BentoML, Yatai, MLflow и Kubeflow мы рассказываем здесь.
Как выбрать наиболее подходящие инструменты и инфраструктурные решения для внедрения MLOps в реальные проекты аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

