Какие источники исходных данных поддерживает Apache Spark для пакетной и потоковой обработки, обеспечивая отказоустойчивые вычисления в большом масштабе средствами SQL и Structured Streaming. Источники данных Apache Spark SQL и структурированной потоковой передачи Будучи фреймворком для создания распределенных приложений обработки больших объемов данных, Apache Spark может подключаться к разным источникам этих...
Информационно-аналитические статьи и новости о технологиях анализа и хранения Больших Данных (Big Data), машинного обучения (Machine Learning), администрирования кластеров (Hadoop, Kafka, Spark, AirFlow), а также реальные истории и лучшие практики их прикладного использования в российских и зарубежных компаниях
Параллельная обработка SQL-запросов в Greenplum
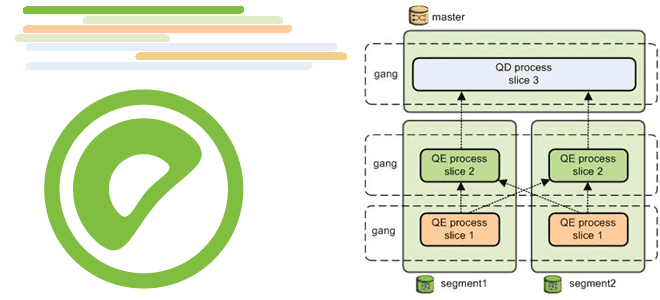
Как координатор Greenplum на мастер-хосте рассылает сегментам планы выполнения запросов, что такое курсор параллельного получения результатов оператора SELECT и каким образом его использовать для аналитики больших данных в этой MPP-СУБД. Особенности рассылки планов SQL-запросов в Greenplum на выполнение Хотя Greenplum основана на PostgreSQL, некоторые механизмы работы этих СУБД отличаются. Например,...
Кэширование в ClickHouse

Чем кэширование в OLAP-системах отличается от OLTP и как устроен кэш запросов ClickHouse: принципы работы, конфигурационные настройки и примеры использования SELECT-оператора. Особенности кэширования в ClickHouse Кэширование является одним из методов повышения производительности, который сокращает время на получение результатов вычислений за счет их хранения в области быстрого доступа. Обычно кэшируются результаты...
Индексация JSON-документов в Greenplum
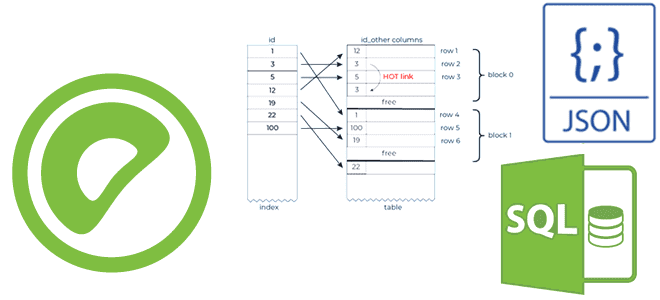
Как Greenplum индексирует JSON-документы, что такое GIN-индекс в PostgreSQL, чем он отличается от B-дерева и хэш-таблицы, когда и как их использовать, а также почему поддерживается только индексация JSONB-полей. Как Greenplum индексирует JSONB-документы Поскольку Greenplum основана на PostgreSQL, она также поддерживает работу со сложными типами данных и может вести себя подобно...
Апрельский релиз ClickHouse 24.4

30 апреля 2024 года опубликован очередной выпуск ClickHouse, который включает 13 новых функций, 16 улучшений производительности и 65 исправлений ошибок. Знакомимся с самими интересными новинками релиза 24.4. Значимые новинки Clickhouse 24.2 Начнем с повседневных операций с таблицами: теперь в ClickHouse можно зараз удалить несколько таблиц со всем их содержимым, используя...
Как работают клиенты реестра схем Apache Kafka: подробный разбор
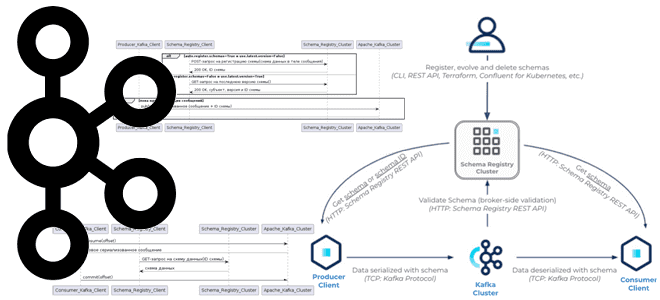
Почему клиентское приложение для публикации сообщений или их потребления из Kafka при использовании реестра схем существует в двух экземплярах, что добавляется к сериализованному сообщению, где хранится идентификатор схемы и другие тонкости работы с Confluent Schema Registry. Сериализация и десериализация сообщений с реестром схем Apache Kafka Недавно я показывала небольшую демонстрацию...
TaskFlow API и традиционные операторы Apache AirFlow: совместное использование
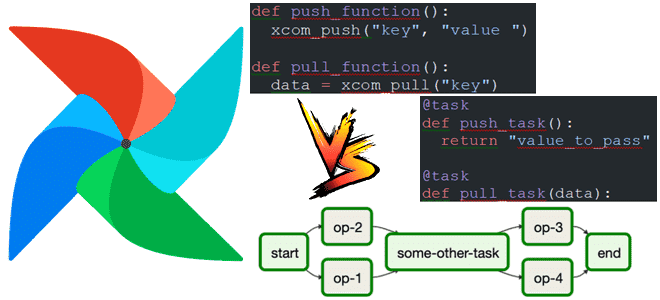
Чем API TaskFlow отличается от традиционных операторов Apache Airflow, можно ли их использовать вместе и как это сделать для более эффективной передачи данных между задачами DAG с помощью механизма XCom: несколько примеров. Что такое API TaskFlow в Apache Airflow Чтобы реализовать конвейер обработки данных в Apache AirFlow, можно использовать традиционные...
Сравнение датафреймов в Apache Spark на примере PySpark-кода

Что такое assert, зачем это нужно в тестировании и отладке, как эта конструкция применяется для сравнения датафреймов в PySpark: примеры работы функций assertDataFrameEqual() и assertSchemaEqual() в Apache Spark. Что такое assert: конструкция тестирования При разработке PySpark-приложения дата-инженер чаще всего оперирует такими структурами данных, как датафрейм. Датафрейм (DataFrame) – это распределенная...
Публикация и потребление AVRO-сообщений с реестром схем Apache Kafka: пример на Python
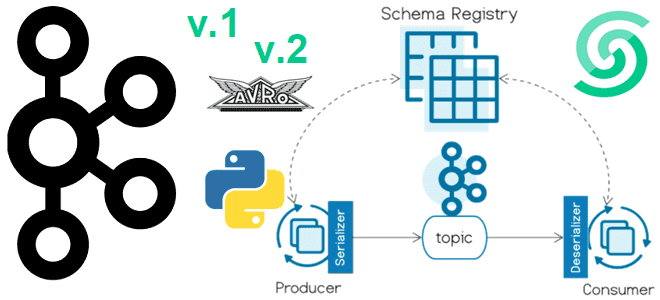
Версионирование схемы сообщений в формате AVRO с использованием реестра схем Apache Kafka и библиотеки confluent_kafka: практический пример на Python в Google Colab. Публикация сообщений в Kafka с использованием реестра схем Недавно я показывала пример использования реестра схем (Schema Registry) Apache Kafka при публикации сообщений. Сегодня рассмотрим версионирование схемы данных в...
Внешние и сторонние таблицы Greenplum: external vs foreign
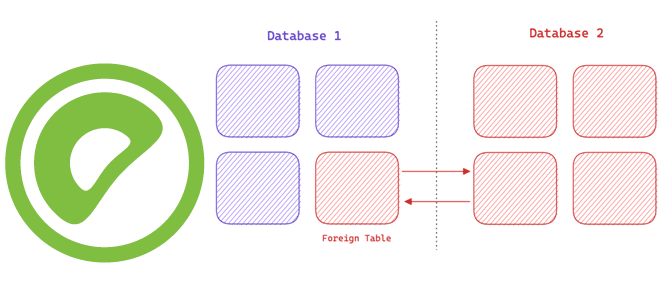
Чем внешняя таблица Greenplum отличается от сторонней, и как они преобразуются друг в друга: организация доступа к данным вне базы, FDW-обертки и протоколы для интеграции MPP-СУБД с другими источниками информации. Сторонняя таблица в Greenplum Термины внешняя (external) и сторонняя (foreign) table похожи, но нюансы их использования в Greenplum отличаются. Такие...