Чтобы сделать наши курсы по Apache NiFi для дата-инженеров еще более полезными, сегодня рассмотрим новые возможности последнего релиза Cloudera Flow Management 2.1.1 на базе этого фреймворка. Выпущенная в апреле 2021 года, платформа Cloudera Flow Management в составе публичного и частного облака предоставляет Apache NiFi версии 1.13.2, включая дополнительные компоненты, а также улучшения и исправления ошибок.
Что такое Cloudera Flow Management и при чем здесь Apache NiFi
Apache NiFi – это мощный GUI-инструмент для создания конвейеров маршрутизации данных. Сотни встроенных процессоров позволяют легко подключаться к любому приложению и преобразовывать структуры и форматы данных в сценариях потоковой и пакетной интеграции. На практике развертывания Apache NiFi обычно начинаются с малого числа пользователей и потоков данных. Но по мере роста своей Big Data инфраструктуры, предприятия сталкиваются с проблемами конкуренции за ресурсы, когда все потоки данных используют один и тот же домен. Чтобы избежать этого, организации начинают создавать изолированные кластеры для разделения потоков данных на основе бизнес-единиц, сценариев использования или показателей SLA. Такое решение устраняет некоторые проблемы, но приводит к дополнительным накладным расходам на управление, затрудняя централизованный мониторинг потоков данных, распределенных по нескольким кластерам.
Кроме того, в зависимости от первоначального размера кластеров, компании могут понадобиться дополнительные вычислительные ресурсы. Хотя узлы NiFi могут быть добавлены в существующий кластер, процесс расширения ИТ-инфраструктуры требует постоянного мониторинга использования ресурсов и эффективности их утилизации с целью определения спроса на безопасное масштабирование. А уменьшение масштаба кластера еще более сложно из-за риска потери данных на списанных узлах. Автоматическое изменение масштаба кластеров NiFi достаточно сложно и требует много времени. Все это вынуждают дата-инженеров и администраторов NiFi тратить много времени на управление кластерной инфраструктурой вместо создания новых потоков данных, актуальных для текущих бизнес-потребностей.
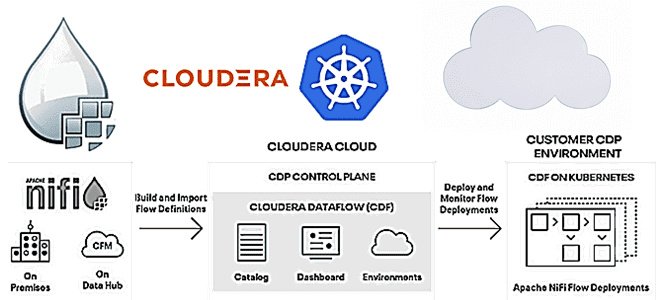
Поэтому в августе 2021 года Cloudera объявила о общей доступности платформы DataFlow для публичного облака с целью улучшения эксплуатации и мониторинга стандартных кластеров Apache NiFi, перегруженных высокопроизводительными потоками Big Data. Теперь пользователям не нужно беспокоиться о масштабировании потоков данных при изменении их объемов и организовывать несколько кластеров NiFi для изоляции отдельных потоков. Вместо трудоемкого процесса создания собственной централизованной системы мониторинга можно воспользоваться облачным сервисом, который легко развертывать существующие потоки данных в масштабируемой среде выполнения с центральной панелью мониторинга, предоставляющей наиболее актуальные метрики для каждого из них [1].
Возможность развертывать, управлять и отслеживать потоки NiFi, работающих в локальных кластерах или публичных облаках на Cloudera Data Platform, и переводить их в Kubernetes на AWS дает следующие ключевые преимущества [2]:
- упрощение развертывания, благодаря мастеру развертывания и каталогу потоков, а также галерее готовых шаблонов для различных бизнес-сценариев;
- автоматическое масштабирование инфраструктуры обработки потоков в соответствии с текущими потребностями;
- изоляция потоков в индивидуальных облачных кластерах предотвращает конкуренцию за вычислительные ресурсы;
- унификация мониторинга нескольких облачных кластеров в единой панели управления администратора;
Все обновления и улучшения Apache NiFi в Cloudera Flow Management 2.1.1 можно структурировать по 3-м категориям [3]:
- средства мониторинга – конечная точка Prometheus, новая задача отчетности QueryNiFiReportingTask для запуска SQL-запросов к данным внутреннего мониторинга NiFi (метрики, статус, происхождение и пр.) и определения места назначения данных (Kafka, СУБД, Prometheus и пр.). Это включает интеграцию с Flink’s Streaming SQL Builder для выполнения SQL-запросов поверх потоков данных для мониторинга NiFi и генерации предупреждений. Также добавлена история статуса узлов NiF.
- новые возможности пользовательского интерфейса, такие как добавление в контекстное меню процессоров команд «Запустить только 1 раз», «Очистить все очереди группы процессов» для рекурсивного удаления всех потоковых файлов в отношениях при наличии у пользователя полномочий на эту операцию. Также добавлен импорт определения потока: перетаскивая группу процессов на холст, можно импортировать определение потока из другой среды. В частности, с помощью команды «Загрузить определение потока» можно импортировать свои потоки в сервисы DataFlow и запускать NiFi в Kubernetes.
- около 40 новых компонентов – процессоры, службы контроллеров и задачи отчетности. Особенно стоит отметить наиболее востребованные на практике процессоры для взаимодействия с Microsoft Azure Data Lake Storage и новый процессор ScriptedTransformRecord, позволяющий определять очень специфичные преобразования обработки данных. Также добавлен распределенный кэш на основе Hazelcast – распределенной сетки данных в памяти, open-source продукт на базе Java. Эта вычислительная платформа управляет данными в операционной памяти и организует обработку в параллельном исполнении для повышения скорости и лёгкости масштабирования.
Далее заглянем внутрь некоторых из нововведений более подробно.
Под капотом Cloudera DataFlow в публичном облаке
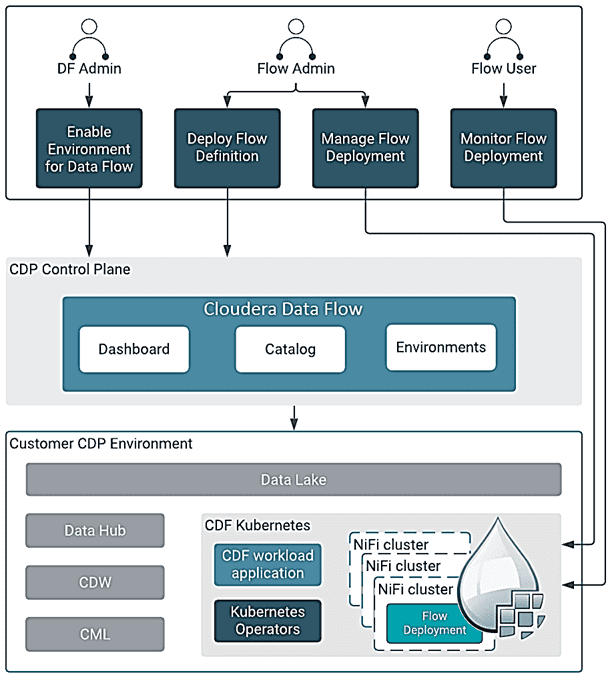
Cloudera DataFlow Management в публичном облаке использует Kubernetes в качестве масштабируемой среды выполнения и по мере необходимости предоставляет кластеры NiFi поверх нее. В основе этого лежит совершенно новый оператор Kubernetes, разработанный с нуля для управления жизненным циклом кластеров Apache NiFi в этой платформе контейнеризации. Когда пользователи создают запрос на развертывание, оператор готовит новый, полностью безопасный кластер NiFi и после его создания также заботится о других аспектах его жизненного цикла, включая обновление и завершение работы.
При отправке пользовательского запроса на развертывание с помощью мастера Cloudera DataFlow Management в публичном облаке подготавливает новое пространство имен в общем кластере Kubernetes в соответствии со заданной спецификацией. Таким образом, каждая строка, отображаемая на панели мониторинга, представляет собой кластер NiFi, работающий в собственном пространстве имен. Используя выделенные пространства имен для каждого развертывания, можно обеспечить изоляцию ресурсов и доменов сбоя между различными потоками данных. При этом в Cloudera DataFlow Management обновления версий NiFi автоматически становятся доступными для всех пользователей, как только Cloudera выпускает их.
Пользователи получают доступ к сервису Cloudera DataFlow Management через средство управления, которая также включает Каталог, Панель мониторинга и Галерею готовых потоков. Пока пользователи инициируют новые развертывания NiFi, фактически они создаются в облачной учетной записи клиента. Такое разделение между инициированием развертываний, мониторингом в средстве управления Cloudera и обработкой данных в облачной учетной записи клиента гарантирует защиту конфиденциальной информации при изменении инфраструктуры.
Прежде чем создавать развертывания NiFi в публичном облаке платформы управления потоками данных Cloudera DataFlow Management, следует импортировать существующие определения в Каталог. Это делается в GUI с помощью команды «Загрузить определение потока», которая создает JSO- файл с его метаданными. Если используется реестр Apache NiFi, определения потоков можно экспортировать и оттуда. Таким образом, возможность экспортировать группу процессов с любого уровня иерархии потоков данных NiFi дает полную гибкость в отношении уровня изоляции, которую следует достичь при их развертывании. После преобразования экспортированного определения потока в независимое развертывание, ему можно выделить ресурсы.
Экспортиров группы процессов из существующего развертывания NiFi, их можно импортировать в каталог потоков – центральный репозиторий для всех определений. Инициируя новое развертывание из центрального каталога потоков, Cloudera DataFlow Management использует мастер, который позволяет пользователям указывать значения параметров (строки подключения, учетные записи для запуска потока и пр.), а также загружать дополнительные зависимости: файлы конфигурации и драйверы JDBC. Эти ресурсы автоматически подключаются и доступны для всех узлов NiFi, устраняя ручное копирование файлов на каждый узел.
Также мастер предоставляет информацию о размере и масштабировании развертывания потока, позволяя пользователям выбрать один из предопределенных размеров узлов и указать их количество. Cloudera DataFlow Management в публичном облаке непрерывно отслеживает использование ЦП в результате развертывания NiFi и автоматически масштабирует по мере необходимости. Даже после создания развертываний пользователи могут настраивать границы масштабирования для уже развернутых кластеров, чтобы реагировать на меняющиеся требования к обработке потоков.
При пошаговом выполнении мастера развертывания пользователи Cloudera DataFlow Management могут определять и отслеживать их ключевые показатели эффективности (KPI), как для всего потока данных, так и для отдельных компонентов NiFi: группы процессов, процессоры и соединения. Каждый KPI может дополнительно запускать предупреждения при выполнении заданного условия. Например, пользователи могут определить KPI для всего потока, который отслеживает метрику «Входящие данные» и запускает предупреждение каждый раз, когда поток получает данные со скоростью менее 1 МБ/с в течение 5 минут. Это важно, поскольку мониторинг потоков данных в традиционных кластерах NiFi является сложной задачей и требует настройки сторонних инструментов мониторинга, чтобы получить глобальное представление обо всех потоках данных.
В публичном облаке Cloudera DataFlow Management каждое развертывание потока можно централизованно контролировать и управлять с помощью наглядной панели мониторинга, откуда можно получить доступ к диспетчеру развертывания. В нем доступны функции обновления значений параметров, изменения конфигурации автомасштабирования и размера, а также редактирования KPI без повторного развертывания потока данных.
В заключение отметим еще одно преимущество Cloudera DataFlow Management, особо важное для начинающих дата-инженеров: галерея готовых шаблонов ReadyFlows для популярных бизнес-сценариев перемещения данных. ReadyFlows можно добавить в центральный каталог и развернуть, как и любое другое определение потока из каталога. После добавления готовых шаблонов потоков данных NiFi в каталог, пользователи могут запустить мастер развертывания и указать необходимые параметры для их настройки, чтобы развернуть свои конвейеры потоковой обработки менее чем за 5 минут, не имея глубокого опыта работы с этим Big Data фреймворком [1]. О лучших практиках разработки и развертывания Data Flow в Apache NiFi на платформе Cloudera читайте в нашей новой статье.
Освойте всю практику администрирования и использования Apache NiFi для современной дата-инженерии на специализированных курсах для разработчиков, ИТ-архитекторов, инженеров данных, администраторов, Data Scientist’ов и аналитиков Big Data в нашем лицензированном учебном центре обучения и повышения квалификации в Москве:
Источники

