
Как турецкая e-commerce компания Trendyol повысила эффективность пакетных вычислений, используя распределенную платформу потоковой обработки событий Apache Kafka вместе с серверной утилитой сбора и фильтрации данных из разных источников Logstash. Пакетная обработка данных и конвейер на Logstash Хотя сегодня все больше организаций переходят на потоковую обработку событий в реальном времени, пакетная...
В данном разделе мы публикуем информационно-аналитические статьи и новости о технологиях Больших Данных (Big Data), машинного обучения (Machine Learning), Data Science, администрировании распределенных кластеров Hadoop, NoSQL, Kafka, Spark, а также реальные истории и лучшие практики их прикладного использования (use cases и best practices) в российских и зарубежных компаниях.
DWH по Кимбаллу и Data Mesh
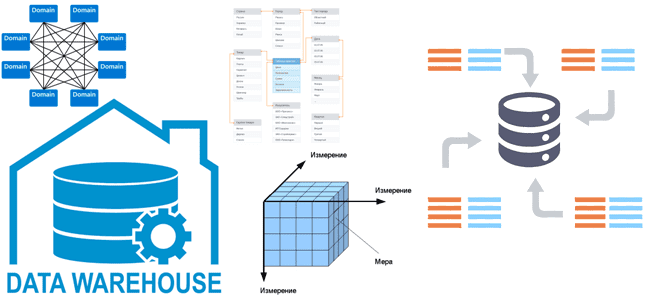
Все архитекторы DWH и многие дата-инженеры знакомы с идеями Ральфа Кимбалла, согласно которым хранилище данных — это сочетание множества различных витрин данных, облегчающих отчетность и анализ важных бизнес-показателей. Читайте далее, как реализовать этот подход при проектировании корпоративного хранилища данных и при чем здесь Data Mesh. КХД по Кимбаллу: доменные витрины...
3 аспекта проектирования схем данных в Greenplum
В этой статье продолжим говорить про лучшие практики работы с Greenplum и рассмотрим тонкости проектирования схем данных в этой MPP-СУБД, которая часто применяется для хранения и аналитики больших данных. Почему надо задавать одинаковые типы данных для столбцов, используемых в SQL-запросах c оператором JOIN, чем хранилище кучи отличается от Append Only,...
MLOps для Apache Flink с MLeap
Сегодня рассмотрим, как реализовать MLOps-идеи при разработке приложений Apache Flink с использованием MLeap, библиотеки сериализации для моделей машинного обучения. Зачем инженеры GetInData разрабатывали для этого свой коннектор и как его использовать на практике. Что такое MLeap и при чем здесь MLOps Будучи популярным вычислительным движком для потоковой аналитики больших данных,...
Криптография на PySpark: PyCryptodome для Apache Spark
Мы уже писали про использование криптографии в Apache Spark. Сегодня в рамках обучения дата-инженеров и разработчиков распределенных приложений рассмотрим, как шифровать столбцы датафрейма в PySpark и расшифровывать их с использованием алгоритма шифрования AES. Основы кибербезопасности: ликбез по шифрованию данных Шифрование данных преобразует данные в другую форму или код, чтобы их...
Регулярные выражения в Apache HBase

Каждый разработчик и дата-аналитик с закрытыми глазами напишет SQL-запрос с регулярными выражениями для поиска данных по шаблону в реляционной базе. А вот в NoSQL-СУБД такая простая задача реализуется довольно сложно. Как написать регулярное выражение в Apache HBase и запустить его на исполнение в CLI-интерфейсе shell-оболочки этого хранилища данных. Что такое...
Ад зависимостей для Python-разработчика: 4 библиотеки для визуализации графа
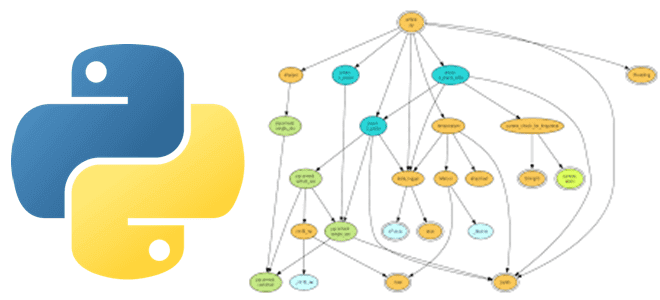
Практически каждый Python-разработчик и Data Scientist использует в своем коде сторонние библиотеки и внешние решения, которые хранятся в разных репозиториях и связаны со множеством других файлов. Этот открытый код настолько распределен, что возникает «ад зависимостей», что сильно осложняет разработку. Читайте, как справиться с этой проблемой, используя методы анализа графов. Проблема...
Профилирование данных и повышение качества DAG-конвейеров Apache AirFlow с Whylogs

Как повысить качество данных и пакетных конвейеров с их обработки в Apache AirFlow с Python-библиотекой Whylogs. Что это за средство регистрации и профилирования, как оно работает, каким образом совместимо с DAG-графом задач Apache AirFlow и чем полезно дата-инженеру. Что такое Whylogs и зачем это Apache AirFlow Apache AirFlow активно используется...
ETL-конвейер передачи данных из MySQL в Hive с Apache NiFi

Сегодня разберем, как автоматизировать наполнение озера данных на HDFS через загрузку таблиц из реляционной базы MySQL в Hive с помощью Apache NiFi. Какие процессоры NiFi следует использовать и зачем предварительно разделять таблицу Apache Hive. Пример ETL-конвейера на процессорах Apache NiFi Apache NiFi часто используется дата-инженерами в качестве средства автоматизации и...
Мониторинг системных метрик Apache Kafka с Iris

Чтобы добавить в наши курсы для администраторов кластера Apache Kafka и разработчиков распределенных приложений еще больше полезных обучающих материалов, сегодня рассмотрим новый инструмент мониторинга системных метрик этой платформы потоковой передачи событий. Что такое проект Iris и чем он отличается от других популярных средств мониторинга состояния Apache Kafka, о которых мы...