 1711
1711 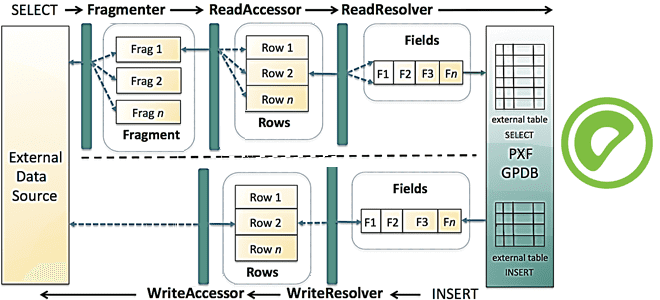
Содержание
Специально для дата-инженеров, разработчиков OLAP-конвейеров и архитекторов DWH на MPP-СУБД Greenplum и Arenadata DB сегодня рассмотрим, что представляет собой PXF, из каких компонентов он состоит и как они взаимодействуют друг с другом, чтобы обеспечить параллельный высокопроизводительный доступ к данным и объединенную обработку запросов к разнородным источникам.
Что PXF и зачем он нужен в Greenplum
С ростом количества локальных хранилищ и облачных сервисов данные находятся во многих разрозненных системах и в разных форматах, что увеличивает сложность и стоимость процессов из аналитической обработки. Поэтому нужны унифицированные средства для масштабируемых запроса исходных хранилищ данных. При этом, когда во внешних системах есть несколько наборов данных, часто вместо продолжительных ETL-операций, требуется лишь небольшое подмножество данных. В этом случае эффективнее объединять наборы данных удаленно и возвращать только результаты, чем согласовывать время и требования к хранилищу для выполнения дорогостоящей операции полной загрузки данных. Для MPP-СУБД Greenplum и Arenadata DB эту задачу можно решить с помощью интеграционного фреймворка PXF (Platform Extension Framework). Прежде чем переходить к PXF, напомним, как работает Greenplum.
Итак, Greenplum – это аналитическая MPP-СУБД без совместного использования ресурсов с несколькими взаимодействующими процессорами. Она управляет хранением и обработкой больших объемов данных, распределяя нагрузку по нескольким серверам для создания массива отдельных баз PostgreSQL, работающих вместе для представления единого образа базы данных. Чем Greenplum отличается от PostgreSQL, смотрите в этой статье.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
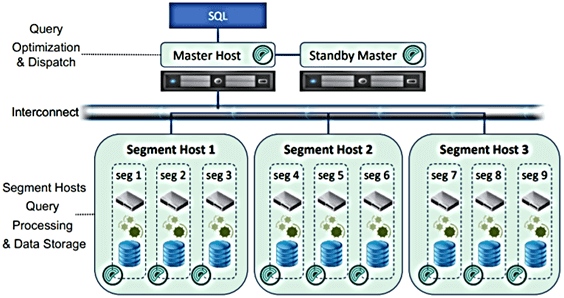
Мастер — это точка входа в Greenplum, куда подключаются клиенты и отправляют операторы SQL-запросов. Мастер координирует работу с другими экземплярами базы данных (сегментами) для обработки и хранения данных. Запрос, отправленный мастеру Greenplum, оптимизируется и разбивается на более мелкие компоненты, которые отправляются в сегменты, где обрабатываются для получения окончательных результатов. За межпроцессное взаимодействие между сегментами отвечают интерконнекты – коммутации сетевого уровня Gigabit Ethernet.
Оптимизатор GPORCA, о котором мы писали здесь, генерирует план с явными директивами перемещения данных, учитывая их стоимость при оптимизации. Программа-исполнитель Greenplum включает в себя несколько конвейерных этапов выполнения с явной связью между сегментами на каждом этапе. Например, многоступенчатый план агрегации используется для параллельного вычисления локальной агрегации в каждом сегменте, затем Greenplum перераспределяет промежуточный результат агрегации на основе столбцов группировки для вычисления окончательного результата.
PXF — это проект с открытым исходным кодом, который обеспечивает параллельный высокопроизводительный доступ к данным и объединенную обработку запросов к разнородным источникам через встроенные коннекторы. Они сопоставляют определение внешней таблицы Greenplum с внешним источником данных, не требуя загрузки больших наборов данных в эту MPP-СУБД. PXF также предоставляет возможность выполнять части оператора запроса в других источниках данных: облачных хранилищах (AWS S3, Google Cloud Storage или хранилище BLOB-объектов Microsoft Azure), распределенных файловых системах типа Hadoop HDFS, NoSQL-хранилищах (Apache Hive, HBase, mongoDB) и реляционных базах (Oracle Database, PostgreSQL, MySQL и пр.). PXF построен на следующих принципах:
- поддержка SQL через интерфейс запросов к внешним источникам данных и к любой управляемой таблице в Greenplum;
- простой и стандартизированный API для регистрации источника и формата данных, информации о пользователе и параметрах форматирования;
- поддержка различных форматов данных – CSV, текст, строковые форматы (JSON, AVRO), колоночные форматы (ORC, Parquet). Подробнее об этом читайте в нашей новой статье;
- независимость от облачной платформы — фреймворк может запрашивать данные из разных облачных хранилищ;
- расширяемость – можно настраивать коннекторами с другими источниками и форматами данных, не влияя на оптимизацию запросов;
- масштабируемость – PXF поддерживает многоядерность и может разбивать, а затем распределять задания по выборке данных из разных внешних источников;
- легкость обновления по мере роста количества источников и форматов данных, фреймворк упрощает обновление независимо от СУБД хоста.
Platform Extension Framework: архитектура и принципы работы
Фреймворк PXF состоит из трех основных компонентов:
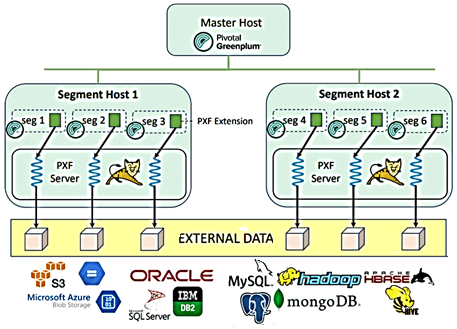
- PXF Extension – клиентская библиотека C, реализующая расширение PostgreSQL, которое работает в каждом сегменте Greenplum и взаимодействует с сервером PXF с помощью вызовов REST API;
- PXF Server – веб-приложение Java, развернутое в Apache Tomcat, подобном веб-серверу контейнере сервлетов с открытым исходным кодом, чтобы запускать и настраивать java сервлеты и JSP страницы. Сервер PXF получает запросы от PXF-расширения и транслирует их во внешние системы.
- Интерфейс командной строки PXF – приложение Go, которое позволяет пользователям управлять серверами PXF в их инсталляциях Greenplum.
Когда пользователь базы данных Greenplum запускает запрос к внешней таблице PXF, создается план запроса, который затем отправляется из главного сервера Greenplum в сегменты Greenplum. Расширение PXF перенаправляет запрос на сервер PXF на том же хосте. В типичной топологии развертывания PXF-сервер размещается на каждом хосте, где выполняется один или несколько процессов сегмента Greenplum. Так сервер PXF получает минимум столько запросов, сколько сегментных процессов, запущенных на хосте, или больше, если запрос сложный и содержит несколько срезов обработки. Как PXF выполняет и оптимизирует эти запросы, читайте в нашей новой статье.
Каждый такой запрос получает назначенный ему поток. CLI-утилита PXF обеспечивает удобный способ администрирования PXF-серверов на Greenplum, позволяя в интерфейсе командной строки запускать команды на определенном сервере, чтобы запустить или остановить его, проверить состояние и пр.
Поскольку PXF поддерживает одновременный доступ к данным на разных серверах, фреймворку нужна информация о каждом из них: адрес, учетные данные, ключи доступа и т.д. Эти параметры подключения к внешнему источнику определяются в XML-файле, например, jdbc-site.xml для MySQL или s3-site.xml для AWS S3. Файлы конфигурации для каждого сервера хранятся в локальной файловой системе, где установлен PXF. Типичная установка PXF помещает двоичные файлы в каталог PXF_HOME, а файлы конфигурации — в каталог PXF_CONF.
При настройке нового сервера следует создать новый каталог внутри PXF_CONF/servers и заполнить файл конфигурации шаблона. Для некоторых внешних источников данных требуются дополнительные зависимости. Например, для доступа к Oracle нужен драйвер Oracle JDBC в папке PXF_CONF/lib, чтобы PXF загружал файлы классов из этого каталога.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Конфигурация сервера использует специальный коннектор PXF для доступа к внешнему источнику данных. Например, коннектор PXF JDBC используется для доступа к таблицам на сервере Oracle, а коннектор PXF Hadoop для доступа к файлам в кластере Hadoop. Конфигурация сервера указывается в параметре SERVER LOCATION URI. Имя сервера определяет расположение файлов конфигурации в локальной файловой системе. Например, если SERVER = hadoop-with-kerberos указан в LOCATION URI, PXF считывает файлы конфигурации *-site.xml из каталога PXF_CONF/servers/hadoop-with-kerberos/. Иногда для доступа к серверу требуются дополнительные файлы, например, если кластер Hadoop защищен безопасным протоколом Kerberos, необходимо предоставить keytab-файл для входа во внешнюю систему.
Для чтения и записи данных из внешних источников данных внутри PXF определены три интерфейса: Fragmenter, Accessor и Resolver. PXF предоставляет несколько реализаций для этих интерфейсов, которые используют разные протоколы связи и поддерживают несколько форматов данных. Чтобы упростить использование, PXF предоставляет концепцию Profile — простого имени, которое инкапсулирует комбинацию конкретных реализаций этих интерфейсов. Разберем их подробнее.
Интерфейсы фреймворка
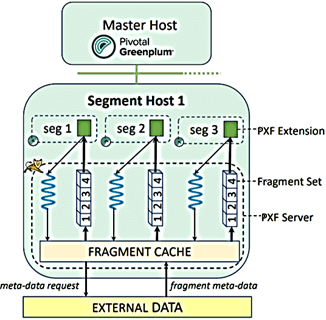
PXF Fragmenter – функциональный интерфейс, который разделяет общий набор данных из внешнего источника данных на список независимых фрагментов для параллельного чтения. Он не извлекает фактические данные, а работает только с метаданными, которые описывают расположение данного фрагмента данных и их смещение в общем наборе. Обработка одного запроса распределяется по всем сегментам Greenplum и нескольким потокам PXF-сервера, которые выполняются независимо друг от друга. Им известно только общее количество сегментов Greenplum и идентификатор процесса, отправившего запрос.
Каждый сегмент Greenplum выполняет два типа вызовов REST к серверу PXF во время запроса к внешней таблице. Один из них делит общий набор данных во внешней системе на фрагменты данных вместе с их метаданными. Процесс получения набора метаданных фрагмента называется фрагментацией. Хотя фрагмент — это наименьший неделимый фрагмент данных, который обрабатывается одним потоком PXF Server, природа фрагментов различна для разных типов внешних систем. Например, фрагмент может быть разделением HDFS для файла в Hadoop HDFS, или подмножеством записей из таблицы JDBC. Процесс получения метаданных о фрагментах зависит от внешней системы, например, вызов Hadoop HDFS NameNode для файла в этой файловой системе или вычисление интервальных сегментов для партиционированной таблицы JDBC. PXF кэширует метаданные во время вызова фрагмента. Полученный набор фрагментов равномерно делится между серверами Greenplum с помощью вызова фрагментации и применения функции хеширования по модулю к набору метаданных фрагментов. Затем каждый сегмент Greenplum выполняет итерацию по назначенному подмножеству фрагментов и выполняет вызов моста для каждого такого фрагмента, чтобы прочитать фактические данные. Отдельный поток сервера PXF обрабатывает каждый вызов моста для одного фрагмента данных. Во время вызова моста поток PXF Server получает метаданные фрагмента из сегмента Greenplum и отвечает за выборку данных из внешней системы для этого фрагмента.
PXF Accessor — это функциональный интерфейс, который отвечает за чтение или запись данных из/во внешние источники, а также преобразование данных в отдельные записи. Поскольку для разных типов внешних источников данных нужны разные протоколы и методы аутентификации, необходимо создать отдельную реализацию средства доступа для каждого типа внешнего сервера. PXF предоставляет различные средства доступа для подключения к удаленным базам данных с помощью JDBC, поставщиков облачных хранилищ объектов и удаленных кластеров Hadoop с использованием клиентских библиотек HDFS. Эти средства доступа PXF могут также читать текст и форматы Parquet, AVRO, CSV. Когда PXF Accessor обрабатывает запрос на получение данных для определенного фрагмента, он сначала извлекает конфигурацию внешнего источника, затем анализирует метаданные для запрошенного фрагмента и использует библиотеки клиентского API соответствующего протокола для запроса необходимых данных. Читаемые данные разбиваются на записи: строки текстового файла, строки в наборе результатов JDBC или записи Parquet, и каждая такая запись в ее собственном формате помещается в общую структуру данных, которая используется в PXF для обмена данными. При работе с внешними источниками (JDBC, Hive, S3), PXF Accessor также отвечает за выполнение некоторых шагов SQL-запроса (predicate pushdown и проецирование столбцов), что мы рассмотрим в следующий раз.
PXF Resolver – это функциональный интерфейс, который декодирует при чтении или кодирует при записи данные из внешней системы в отдельные поля. Затем он отображает типы данных и значения полей в формат, понятный Greenplum или внешней системе. После того, как запись обработана преобразователем, она может быть преобразована в оперативное представление (CSV или двоичное) и отправлена в Greenplum для повторного создания в виде кортежа или в нужный формат, чтобы записать во внешнюю систему. Реализации обычно зависят от форматов данных. Например, PXF предоставляет преобразователи для строк CSV, столбцов JDBC ResultSet, записей Parquet и AVRO, а также документов JSON. При чтении текстовых файлов можно не изменять данные и позволить Greenplum выполнять их постобработку — PXF имеет встроенные преобразователи для этого.
Профиль PXF представляет собой простое именованное сопоставление, которое представляет протокол для подключения к внешнему источнику данных и формат, который следует обработать. Например, для чтения текстового файла из AWS S3 пользователь указывает профиль s3: text, а для чтения файла Parquet из HDFS требуется профиль hdfs: parquet. Пользователи указывают значение параметра профиля при определении внешней таблицы Greenplum. Во время выполнения PXF получает значение параметра профиля с запросом данных от Greenplum и обращается к конфигурации системы PXF, чтобы выбрать подходящую реализацию Fragmenter, Accessor и Resolver для извлечения и обработки данных.
Администрирование Greenplum - Arenadata DB
Код курса
GRAD
Ближайшая дата курса
27 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Наконец, важным компонентом интеграционного фреймфорка является коннектор –логическая группа из нескольких Fragmenter’ов, Accessor’ов, Resolver’ов и профилей, которая позволяет пользователям обрабатывать данные из внешнего источника конкретного типа. Хотя у него нет конкретного технического представления, концепция коннектора понятно описывает общие возможности PXF при работе с внешними данными. PXF предоставляет следующие встроенные коннекторы для внешних систем:
- JDBC для доступа к данным из внешних СУБД с драйвером JDBC (Oracle, MySQL, Postgres, Hive и пр.);
- облачный коннектор для доступа к данным в Amazon S3, облачном хранилище Google, Azure Data Lake, хранилище BLOB-объектов Microsoft Azure и пр.;
- Hadoop для поиска данных в файлах HDFS;
- Hive — считывает данные из Hive-таблиц путем доступа к метаданным в Hive MetaStore и обращения к базовым файлам;
- HBase — принимает данные в таблицах Apache HBase
В следующий раз мы продолжим разбираться с Platform Extension Framework и рассмотрим особенности выполнения SQL-запросов к внешним таблицам. Здесь вы можете прочитать, как PXF помогает Greenplum читать и записывать данные в формате Apache AVRO. А освоить практику администрирования и эксплуатации Greenplum с Arenadata DB для эффективного хранения и аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

