Сегодня продолжим разбираться с интеграционным фреймворком Greenplum и рассмотрим, как PXF реализует SQL-запросы к различным OLAP и OLTP-источникам, поддерживая разные форматы данных. Зачем создавать внешнюю таблицу для Greenplum и какие параметры при этом указывать, а также чем хороша технология оптимизации pushdown.
SQL и PXF: интеграция Greenplum с внешними источниками на уровне таблиц
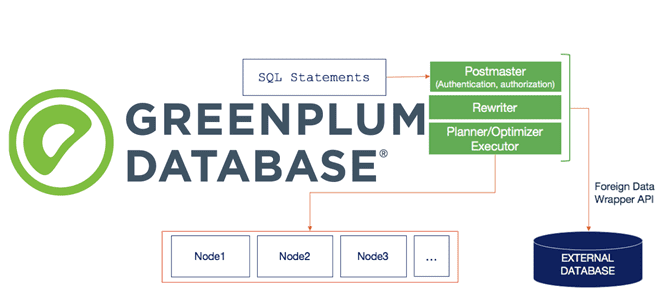
Напомним, Platform Extension Framework (PXF) позволяет пользователям Greenplum запрашивать внешние источники данных с помощью встроенных коннекторов с помощью параллельного доступа с высокой пропускной способностью. При этом PXF также предоставляет возможность выполнять части оператора запроса в других системах: транзакционных или аналитических СУБД типа PostgreSQL, MySQL, Oracle, Apache Hive и пр. Также фреймворк поддерживает множество форматов данных, от неструктурированных (CSV и текст) до строковых (JSON и AVRO) и столбцовых (ORC и Parquet), позволяя работать с облачными объектными хранилищами (AWS S3, Azure Blob Starage, Google Cloud Storage) и файловыми системами как Apache Hadoop. По сути, PXF предоставляет SQL-интерфейс для запросов к сторонним системам, а его встроенные коннекторы сопоставляют определения внешних таблиц Greenplum с источниками данных в различных форматах и структурах.
Platform Extension Framework реализует pxf-протокол Greenplum, который можно использовать для создания внешней таблицы, ссылающейся на данные во внешнем хранилище. После настройки PXF и назначения привилегий пользователь через команду CREATE EXTERNAL TABLE может создать внешнюю таблицу по pxf-протоколу. Синтаксис создания внешней таблицы следующий:
CREATE [WRITABLE] EXTERNAL TABLE <table_name>
(<column_name><data_type> [, ..]
| LIKE <other_table >)
LOCATION('pxf://<path-to-data>?PROFILE=<profile_name>
&SERVER=<server_name>[&=[<custom-option>=<value>[...]]')
FORMAT '[TEXT|CSV|CUSTOM]' (<frornatting-properties>);
Рассмотрим его более подробно:
- LOCATION определяет pxf-протокол как URI, который идентифицирует путь к расположению внешних данных. Например, если внешнее хранилище данных – это распределенная файловая система Apache Hadoop, то LOCATION – это абсолютный путь к конкретному файлу HDFS. Если данные хранятся в Apache Hive, то LOCATION определяет имя таблицы Hive с указанием ее схемы.
- PROFILE определяет профиль для доступа к данным, например, JDBC для реляционных СУБД с этим коннектором. Профиль PXF – это простое именованное сопоставление, которое представляет протокол для подключения к внешнему источнику данных и формат, который следует обработать. Для чтения текстового файла из AWS S3 нужно указать профиль s3:text, а для файла Parquet из HDFS — hdfs:parquet. Во время выполнения PXF получает значение параметра профиля с запросом данных от Greenplum и обращается к конфигурации системы PXF, чтобы выбрать подходящую реализацию Fragmenter, Accessor и Resolver для извлечения и обработки данных, о чем мы рассказывали здесь.
- SERVER предоставляет указанную конфигурацию сервера, необходимую PXF для доступа к внешнему источнику данных: расположение сервера, учетные данные и пр.
Например, если данные хранятся в MySQL, обращение к ним из Greenplum через PXF будет выглядеть так:
CREATE READABLE EXTERNAL TABLE recent_sales
(id int, sdate date, amt decimal(10,2))
LOCATION ('pxf://company.salesdata? PROFILE=Jdbc&SERVER=mysql-db')
FORMAT 'CUSTOM' (FORMATTER='pxfwritable_import');
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
24 июня, 2024
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Оптимизация запросов
PXF поддерживает внутреннюю (на уровне планировщика) технологию оптимизации запросов при выборке внешних данных под названием pushdown. При этом в запросе SELECT с условием WHERE извлекаются ограничения и передаются во внешний источник данных для фильтрации. Такая оптимизация значительно сокращает объем данных, которые необходимо получить из удаленной системы. Для заданного пользовательского запроса мастер Greenplum создает дерево плана запроса, которое затем отправляется сегментам. Оператор внешнего просмотра в плане запроса имеет скалярные выражения, обозначающие предикат, по которому сокращаются входные кортежи.
Разные системы-источники поддерживают различные операторы скалярного сравнения, а также типы данных. Например, Apache Hive поддерживает только текстовые и интегральные типы данных для фильтрации разделов, а HBase не поддерживает предикаты OR. Чтобы pushdown-оптимизация была корректной, коннекторы PXF преобразуют предикат Greenplum в соответствующее условие фильтра, поддерживаемое внешней системой, и игнорируют предикаты, несовместимые с внешней системой, откладывая обработку любой дополнительной фильтрации. Если предикат включен, PXF дополняет предикат до внешнего запроса. Включить или отключить pushdown-фильтрацию для всех протоколов внешних таблиц, в т.ч. pxf, можно установив параметр конфигурации сервера
gp_external_enable_filter_pushdown: SHOW gp_external_enable_filter_pushdown; SET gp_external_enable_filter_pushdown TO 'on';
Колоночные форматы данных (ORC и Parquet) и больше подходят для аналитических рабочих нагрузок, требующих проецирования и группировки, а также высокой степени сжатия. Поэтому PXF при доступе к таким данным выбирает только спроецированные столбцы, что значительно снижает задержку, устраняя затраты на ненужные операции ввода-вывода с внешнего диска. PXF позволяет пользователям определять собственный запрос к данным во внешних источниках. JDBC-коннектор Platform Extension Framework выполняет этот запрос при получении данных для соответствующей внешней таблицы Greenplum. Рассмотрим пример: таблицы клиентов и заказов, хранящиеся во внешней СУБД MySQL, которые нужно запросить для Greenplum.
Сперва следует определить эти таблицы как внешние через pxf-протокол:
CREATE READABLE EXTERNAL TABLE customers
(id int, name text, city text, state text)
LOCATION ('pxf://customers?PROFILE=Jdbc&SERVER=mysql-db')
FORMAT 'CUSTOM' (formatter='pxfwritable_import');
CREATE READABLE EXTERNAL TABLE orders
(amount int, month int, customer_id int)
LOCATION ('pxf://orders?PROFILE=Jdbc&SERVER=mysql-db')
FORMAT 'CUSTOM' (formatter='pxfwritable_import');
Чтобы создать ежемесячный отчет по итогам продаж, нужно соединить таблицу клиентов с таблицей продаж по ключу «идентификатор клиента». Работу по соединению таблиц и вычислению агрегатов можно сделать сразу в Greenplum. Но для этого примера и многих случае в реальности более выгодно запускать соединения и агрегаты во внешней базе данных, а затем просто возвращать результаты в Greenplum. Это позволит избежать накладных расходов на отправку всего набора данных из MySQL по сети в Platform Extension Framework, а затем в Greenplum, а PXF не придется обрабатывать каждую запись обеих таблиц и тратить на это вычислительные ресурсы.
Таким образом, выполнение пользовательских запросов, соединений и агрегирования данных, полностью находящихся в удаленной системе, становится основной целью функции именованных запросов в PXF. Это особенно полезно, если внешние данные управляются Apache Hive в кластере Hadoop. Когда наборы данных огромны, как это обычно бывает в Big Data, кластер Hadoop имеет больше доступных вычислительных ресурсов, чем Greenplum. Поэтому использование мощности и ресурсов Hadoop для обработки данных и получения результатов с Apache Hive Server2 через коннектор JDBC отлично показывают преимущества именованных запросов PXF.
Однако, разрешение пользователю Greenplum указывать SQL-запрос в поле LOCATION при определении внешней таблицы создаст проблемы с безопасностью, особенно для атак типа «SQL-инъекция» и потребует, чтобы PXF проанализировал отправленный SQL-запрос на наличие таких уязвимостей. Вместо этого можно позволить пользователям предварительно определять свои запросы и сохранять их в текстовом файле в каталоге конфигурации PXF-сервера для внешнего источника. Это оставляет проверку правильности и безопасности SQL-запроса администратору Greenplum, который отвечает за управление файлами конфигурации Platform Extension Framework.
Далее текст запроса помещается в файл с расширением .sql и добавляется в каталог конфигурации PXF для сервера внешней СУБД, например, MySQL. А пользователь Greenplum может ссылаться на этот запрос по имени файла при определении внешней таблицы:
CREATE READABLE EXTERNAL TABLE sales_summary
(name text, city text, month int, total int)
LOCATION ('pxf://query:sales?PROFILE=Jdbc&SERVER=mysql-db')
FORMAT 'CUSTOM' (formatter='pxfwritable_import');
Далее пользователь Greenplum может просматривать результаты запроса как внешние таблицы в любой команде SELECT, например, SELECT * FROM sales_summary. При этом имя запроса, указанное в URI LOCATION, имеет префикс query: string. Это указывает PXF, что при обработке запроса для этой внешней таблицы нужно прочитать текст запроса в файле с именем sales.sql в каталоге конфигурации сервера и отправить его на удаленный сервер. После того, как удаленный сервер выполняет предопределенный запрос и возвращает данные, PXF пересылает его Greenplum для представления результата. Также Platform Extension Framework позволяет внешнему оператору применять внутренние оптимизации, включая pushdown. Читайте в нашей новой статье, как Greenplum вместе с Platform Extension Framework и Apache MADlib используются для классификации изображений с помощью алгоритмов глубокого обучения.
Администрирование Greenplum / Arenadata DB
Код курса
GRAD
Ближайшая дата курса
13 мая, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Узнайте больше про администрирование и эксплуатацию Greenplum с Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве: