
В свежем релизе Apache Kafka 3.2.0, который вышел 17 мая 2022 года, о чем мы писали здесь, есть много интересных улучшений для повышения устойчивости потоковых приложений. Почему важна новая фича назначения резервных задач с учетом стоек и как разработчик с дата-инженером могут использовать в помощь администратору кластера: разбор rack awareness в Kafka Streams на примере Kubernetes-инфраструктуры финтех-компании Wise.
Что такое Rack awareness в Apache Kafka 3.2.0 и как это устроено
Вычислительные узлы в центре обработки данных часто группируются в стойки для обеспечения изоляции. Каждая стойка может находиться в своей локации и иметь собственный источник питания. Когда задачи правильно реплицируются между стойками, это обеспечивает отказоустойчивость: если стойка выходит из строя, оставшиеся стойки могут продолжать обслуживать трафик. Впервые для Apache Kafka эта идея была реализована еще в 2016 году, а спустя 6 лет, в релизе 3.2.0 поддержана и для назначения задач на уровне приложения Kafka Streams.
С мая 2022 года Kafka Streams может распределять резервные реплики по отдельным стойкам, используя теги в конфигурации приложения. Эта функция позволяет назначать задачи репликации на разные стойки для обеспечения отказоустойчивости. Например, клиенты Kafka Streams могут быть помечены кластером или облачным регионом, где они работают, чтобы пользователи могли указать теги, которые следует использовать для распространения резервных реплик с учетом стоек, задав конфигурацию rack.aware.assignment.tags. Во время назначения задачи Kafka Streams постарается распределить резервные реплики по ее разным измерениям, чтобы повысить отказоустойчивость в случае выхода из строя всей стойки. Это пригодится, например, для обеспечения распределения реплик по разным зонам доступности в провайдере облачного хостинга.
Rack awareness в Kafka Streams работает следующим образом: количество задач зависит от количества реплик на стойке:
NUM_STANDBY_REPLICAS = x
totalTasks = x+1 (replica + active)
При этом соблюдаются следующие условия:
- если идентификатор стойки не указан, кластер будет вести себя «как обычно», т.е. без знания о стойке;
- если всем узлам присвоен один и тот же идентификатор стойки: кластер будет вести себя без учета стойки;
- если общее число задач меньше или равно количеству стоек, то каждая задача реплики назначается отдельной стойке;
- если общее число задач больше количества стоек, то задачи сначала будут назначены на разные стойки, а затем они будут назначаться наименее загруженному узлу во всем кластере.
Также в релизе Apache Kafka 3.2.0 в StreamsConfig добавлена конфигурация RACK_ID_CONFIG, которая помогает «липкому разделителю» StickyPartitionAssignor назначать задачи так, чтобы никакие две задачи-реплики не находились в одной стойке, если это возможно. Это также помогает поддерживать липкость в стойке, повышая отказоустойчивость потокового stateful-приложения. Чтобы наглядно проиллюстрировать важность этого решения, рассмотрим пример британской финтех-компании TransferWise, которая активно использует приложения Kafka Streams для потоковой обработки событий.
Под капотом Kafka Streams: тонкости назначения задач до версии 3.2.0
Сперва рассмотрим, как активные и резервные задачи управляются в Kafka Streams. Когда приложение Kafka Streams подписывается на топик, оно создает задачу. Задача может обрабатывать один или несколько разделов топика. Один поток может выполнять одну или несколько задач. В случае вычислений с отслеживанием состояния, таких как агрегирование, подсчет, объединение и пр., каждая задача может иметь связанное с ней постоянное состояние. Такие задачи называются задачами с отслеживанием состояния (stateful). Обычно состояния небольшие по размеру, но могут быть и довольно объемными. Например, в Wise есть много заданий по потоковой обработке на основе Kafka Streams, которые обрабатывают состояние объемом более 1 ТБ.
В Kafka Streams постоянное состояние управляется встроенной базой данной RocksDB и поддерживается соответствующими разделами журнала изменений для обеспечения отказоустойчивости. Подробнее об этом мы писали здесь и здесь. Обычно в производственной среде задачи распределяются между несколькими узлами, так что каждый из них обрабатывает меньшую часть обработки. При отказе одного узла задачи, выполняемые на отказавшем узле, должны быть перенесены на исправные узлы. Прежде чем возобновить обработку stateful-задач, Kafka Streams должна восстановить их состояние из разделов лога изменений. Чем больше состояние у задачи, тем больше времени требуется для миграции на другие узлы. Пока процесс переноса задачи не будет завершен, обработка событий в реальном времени останавливается и у разделов, за которые отвечал отказавший узел, возникает простой.
Для ускорения процесса восстановления состояния путем создания «горячей» резервной задачи на узле, отличном от активного в Kafka Streams есть параметр конфигурации num.standby.replicas. Резервные задачи постоянно копируют состояние из соответствующего топика лога изменений и пытаются сопоставить локальное состояние с активным, чтобы обеспечить согласованность и актуальность. Резервные задачи сокращают время восстановления, т.к. в случае сбоя узла Kafka Streams переносит активную задачу на узел, где находится резерв. Поэтому перенесенная задача не должна полностью восстанавливать состояние из раздела лога изменений, что сокращает время отработки отказа задачи.
В инфраструктуре Wise ежедневно выполняется сотни stateful-заданий на основе Kafka Streams. Задания потоковой обработки запускаются как Statefulsets в самоуправляемых кластерах Kubernetes (k8s-cluster-1, k8s-cluster-2). О тонкостях развертывания stateful-приложений Kafka Streams в кластерах Kubernetes мы писали здесь. В Wise каждый под работает с постоянными томами, поддерживаемыми дисками EBS. Каждый кластер Kubernetes развертывает поды в 3-х зонах доступности (AZ-A, AZ-B, AZ-C). Если есть 3 пода на кластер Kubernetes, то в каждой зоне доступности будет 2. Основная проблема была в том, что до Apache Kafka 3.2 распределение резервных задач основывалось исключительно на наименее загруженных клиентах Kafka Streams, которые определялись числом назначенных им задач. Затем распределитель резервных задач в Kafka Streams назначал резервную задачу клиенту с наименьшим их количеством. В рассматриваемом примере есть 2 пода в каждой зоне доступности, и если настроить num.standby.replicas=1, то активная и резервная задачи смогут оказаться в одной зоне доступности.
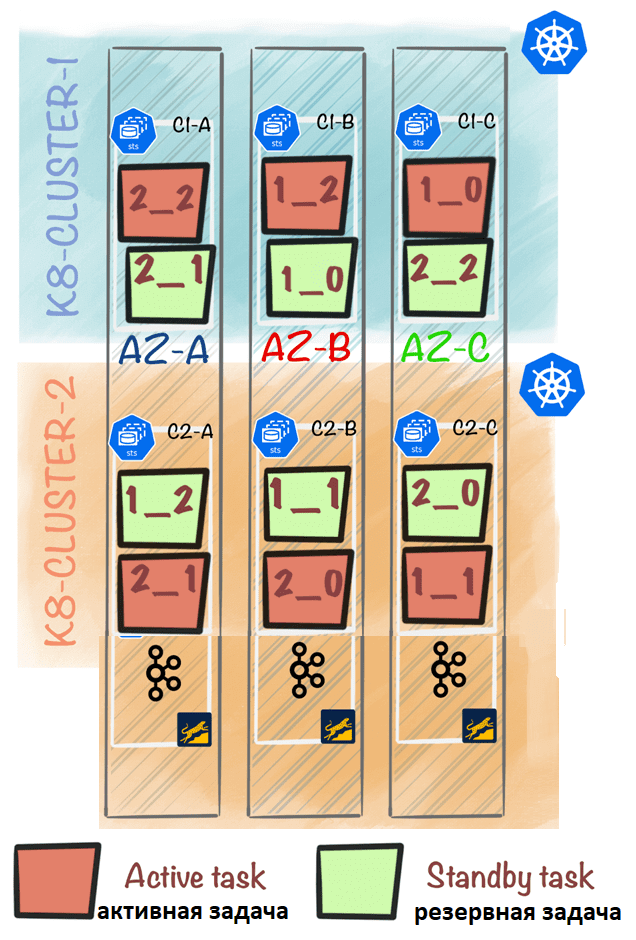
В рассмотренном примере активные и резервные задачи для 2_1 расположены в AZ-A. Эта установка создавала проблему в облачной среде. В случае сбоя зоны доступности терялись активные и резервные задачи в этих подах, что сильно замедляло процесс восстановления, особенно для больших stateful-приложений. Чтобы устранить эту проблему, пользователи настраивали num.standby.replicas так, чтобы оно превышало определенное количество экземпляров Kafka Streams в каждой зоне доступности. В нашем примере можно установить num.standby.replicas=2,т.е. 2-я резервная задача будет размещена в другой зоне доступности по сравнению с активной. Но это решение оказывалось довольно дорогостоящим из-за большого объема хранения данных.
Назначение резервных задач с мая 2022: практический пример
С релиза платформы 3.2.0 пользователи Kafka Streams могут настраивать свои приложения с учетом стойки, размечая их произвольными тегами, соответствующими информации о том, где работает экземпляр Kafka Streams, например, зоне доступности. Kafka Streams будет использовать эту информацию для определения наиболее оптимального распределения резервных задач. За это отвечают 2 дополнительных параметра конфигурации: client.tag.* и rack.aware.assignment.tags. Осведомленность о стойке работает на основе максимальных усилий. Алгоритм резервных задач с учетом стойки вычисляет наиболее оптимальное распределение резервных задач на основе доступных экземпляров Kafka Streams и конфигурации их тегов. Возвращаясь к примеру компании Wise, рассмотрим, как можно применить информацию о стойке, чтобы получить более отказоустойчивую настройку потоковых stateful-приложений.
Параметр client.tag.* позволяет пользователям определять произвольные теги «ключ-значение» для своих приложений Kafka Streams. Например, в Wise установили зону доступности и кластер Kubernetes в виде тегов следующим образом:
client.tag.zone=az-a
client.tag.cluster=k8s-cluster-1
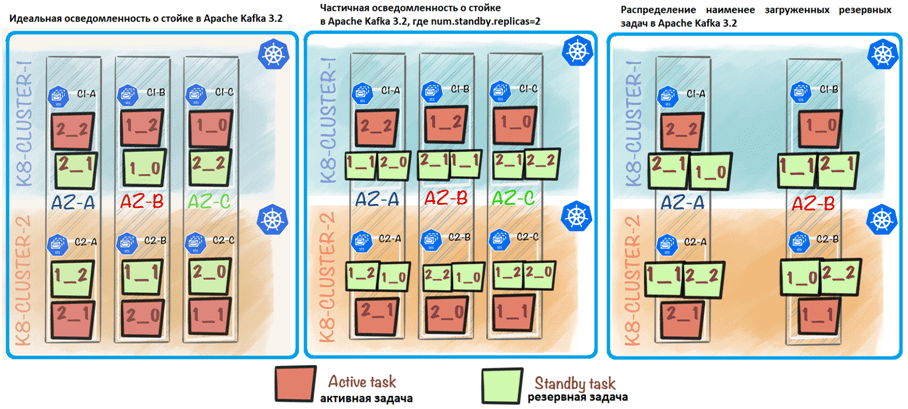
Параметр rack.aware.assignment.tags позволяет пользователям указать, какие клиентские теги следует учитывать при расчете распределения резервных задач с учетом стойки. Можно рассмотреть как теги зоны, так и теги кластера. Например, если num.standby.replicas=1, Kafka Streams обеспечит создание резервной реплики в экземпляре, который отличается от активного тегами зоны и кластера. Это то, что можно назвать идеальной осведомленностью о стойке — когда все резервные задачи расположены на разных тегах по сравнению с активными и другими резервными задачами. Новое распределение резервных задач обеспечивает более быстрое восстановление в случае сбоя AZ и сбоя одного кластера Kubernetes.
Если указать num.standby.replicas=2, вторая резервная задача больше не будет рассматривать тег кластера, так как для этого распределения недостаточно его доступных значений. Тем не менее, он будет учитывать только тег зоны, поскольку есть 3 различных значения для этого тега. Таким образом, 2-я резервная задача будет назначена другой зоне доступности, чем активная и 1-я резервная задачи. Можно рассматривать это как частичную осведомленность о стойке, когда не все резервные задачи расположены на разных тегах по сравнению с активными и другими резервными задачами.
Поскольку в примере Wise есть только 2 уникальных значения тега кластера, можно добиться «идеального» распределения только при назначении 1-й резервной задачи. Идеальное распределение для 1-й резервной задачи может быть достигнуто, если назначить резервную задачу клиенту, расположенному в другом кластере и зоне, чем активная задача. Нельзя учитывать тег кластера для назначения 2-й резервной задачи, потому что 1-я резервная задача уже будет назначена в другом кластере по сравнению с активным. Это означает, что все доступные значения тега кластера уже использованы. Учет тега кластера для назначения 2-ой резервной задачи фактически означает исключение всех клиентов.
Вместо этого для 2-ой резервной задачи можно добиться только частичной осведомленности о стойке на основе тега зоны. Без учета тега кластера для назначения 2-й резервной задачи, частичную осведомленность о стойке можно удовлетворить, поместив 2-й резервный клиент в другой тег зоны, чем активные и соответствующие резервные задачи. Зона в любом теге кластера является допустимым кандидатом для частичной осведомленности о стойке, поскольку цель обеспечения отказоустойчивости — распределить клиентов по разным тегам зоны. Также можно добиться идеальной осведомленности о стойке, используя 3-ий кластер Kubernetes.
Таким образом, новое средство назначения резервных задач с учетом стойки может по умолчанию использовать «наименее загруженное» назначение резервных задач, если невозможно достичь даже «частичной осведомленности о стойке». Например, если есть только 2 зоны доступности и num.standby.replicas=2, 2-й резерв по умолчанию будет наименее загруженным клиентом, потому что не хватает значений тега зоны.
Можно сказать, что резервные реплики — это уникальная функция Kafka Streams, которая позволяет потоковым stateful-приложениям восстанавливаться после сбоев намного быстрее, чем в большинстве других сред. Как показал опыт компании Wis, новая фича Apache Kafka 3.2 обеспечивает гибкий способ управления распределением резервных задач даже при работе в нетривиальной инфраструктуре. Это достигается путем итеративного вычисления распределения резервных задач на основе доступных экземпляров Kafka Streams, их тегов и желаемого количества резервных реплик. Так дата-инженер и разработчик распределенных приложений помогают администратору кластера справляться со сбоями и повышать доступность Big Data систем.
Больше практических кейсов по администрированию и эксплуатации Apache Kafka для потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

