
Поскольку наши курсы по Apache Spark предполагают практическое обучение с глубоким погружением в особенности разработки и настройки распределенных приложений, сегодня рассмотрим, как именно выполняются кластерные вычисления в рамках этого Big Data фреймворка. Читайте далее, из чего состоит архитектура Spark-приложения, как связаны SparkContext и SparkConf, а также зачем ограничивать размер драйвера и потребляемой им памяти.
Как устроено приложение Apache Spark: краткий обзор run-time архитектуры
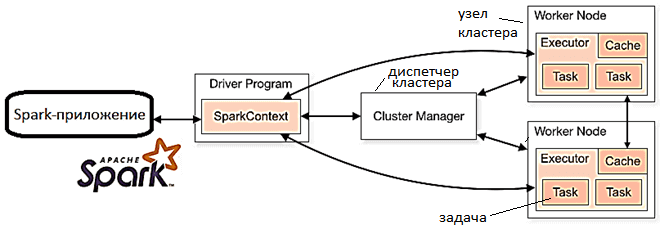
Приложение Apache Spark — это автономное вычисление, которое включает в себя процесс драйвера (driver) и набор процессов-исполнителей (executor). Здесь процесс драйвера запускает функцию main() на узле кластера и отвечает за следующие аспекты:
- управление информацией о приложении;
- отклик на команды, заданные программой или введенные пользователем;
- анализ, распределение и планирование работы исполнителей.
Именно процесс драйвера считается «сердцем» Spark-приложения, т.к. он управляет всей необходимой информацией в течение его жизненного цикла. А исполнители отвечают за фактическое выполнение работы, которую им выделяет драйвер [1]. Весь процесс начинается с драйвера, который преобразует пользовательскую программу в задачи – единицы вычислительной активности, которые вместе образуют задание (job). Из программы пользователя фреймворк строит логический ориентированный ациклический граф (DAG, Directed Acyclic Graph) операций и процессов. О том, как фактическое расположение драйвера определяет режим развертывания Spark-приложения, читайте в нашей новой статье.
Таким образом, архитектуру любого Spark-приложения составляют следующие компоненты [2]:
- драйвер — главный или мастер-процесс (master), который преобразует программы в задачи и планирует их для исполнителей с помощью планировщика задач (Task Scheduler);
- диспетчер кластеров или кластерный менеджер (Cluster Manager) — ядро фреймворка, которое позволяет запускать исполнители, а иногда и драйверы. Именно здесь планировщик (Scheduler) планирует действия и задания приложения в режиме FIFO (First Input – First Output), т.е. прямой очереди.
- исполнители (подчиненные процессы, Slave Processes) — сущности, на которых выполняется отдельная задача из задания. Запущенные исполнители работают до завершения жизненного цикла приложения, а в случае отказа перехватывают работу друг друга, чтобы продолжить выполнение задания.
- RDD (Resilient Distributed Datasets) – одна из основных структур данных фреймворка, которая лежит в основе структур более высокого уровня абстракции – DataSet и DataFrame. О сходстве и различиях RDD, DataSet и DataFrame мы рассказывали здесь, здесь, здесь и здесь. RDD — это распределенная коллекция неизменяемых наборов данных на разных узлах кластера, разделенная на один или несколько разделов (partition), чтобы добиться параллелизма внутри приложения за счет локальности данных. Преобразования повторного разделения (repartition) или объединения (coalesce) позволяют сохранить количество разделов.
- DAG (Directed Acyclic Graph) – направленный ациклический граф операторов, который генерирует фреймворк, когда пользовательский код введен в консоль. При запуске действия с RDD, фреймворк отправляет DAG в планировщик графов (DAGScheduler), где графы операторов разделяются на этапы задачи (stages). Каждый этап может содержать задания, основанные на нескольких разделах входных данных. DAGScheduler объединяет эти графы операторов в конвейер (pipeline). Например, граф оператора Map составляет граф для одного этапа, который переходит в Планировщик заданий в диспетчере кластеров для их выполнения. Далее эта задача исполняется worker’ом или executor’ом на ведомом устройстве (slave).
Увеличение количества исполнителей в кластерах повышает уровень параллелизм при обработке заданий, но для наиболее эффективного выполнения распределенных вычислений данные должны быть оптимально распределены между исполнителями. Например, RDD позволяет с незначительным трафиком перетасовать данные между исполнителями на разных узлах кластера через разделение по принципу «ключ-значение». Фреймворк гарантирует, что набор ключей всегда будет отображаться в одном узле, снижая накладные расходы на передачу данных между машинами [2].
Конфигурация, контекст, настройка драйвера: с чего начать разработку Спарк-приложения
Настройка Spark-приложения – это определение свойств объекта SparkConf, часть из которых для распределения ресурсов в кластере, таких как количество, размер памяти и ядра для исполнителей на рабочих узлах, передается при инициализации SparkContext – точке входа в функциональные возможности фреймворка. Любое приложение прежде всего создает SparkContext в драйвере Спарк, чтобы получить доступ к кластеру с помощью диспетчера ресурсов, например, Standalone, Apache YARN или Mesos. Перед созданием SparkContext необходимо создать SparkConf, где задаются главный URL-адрес и имя приложения как произвольная пара «ключ-значение», настраиваемые с помощью метода set() [3].
Следующий код показывает пример создания SparkConf и SparkContext [1]:
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
public class AppConfigureExample {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster(“local[2]”);
conf.set(“spark.app.name”, “SparkApplicationName”);
SparkContext sc = new SparkContext(conf);
}
}
Важно помнить, что для каждой JVM в любой момент времени может быть активен только один SparkContext. Поэтому, прежде чем создавать новый, остановить активный, с помощью метода stop(). Для вышерассмотренного примера с участком кода эта команда будет выглядеть так: sc.stop(); [3].
По умолчанию размер драйвера Spark равен 1 ГБ — это максимальный предел общей суммы размеров сериализованных результатов всех разделов для каждого действия. При превышении этого лимита отправленные задания будут остановлены. При задании свойства spark.driver.maxResultSize равным 0, максимальное ограничение на использование снимается. Но при превышении доступного значения в драйвере может возникнуть нехватка памяти. Установка максимального ограничения на использование памяти в Spark Driver выполняется через метод set() объекта SparkConf: conf.set(“spark.driver.maxResultSize”, “200m”).
Однако, на практике недостаточно просто задать максимальный лимит размера драйвера. Следует также через метод set() объекта SparkConf установить свойство spark.driver.memory – наибольшее значение памяти, который он может потреблять. Например, инструкция conf.set(“spark.driver.memory”, “600m”) ограничивает память Спарк-драйвера в 600 МБ.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
13 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Примечательно, что при запуске Spark-приложения в клиентском режиме, это свойство должно быть установлено с помощью параметра командной строки –driver-memory. И, конечно, стоит помнить, что в приложении Apache Spark есть фиксированный размер стека и фиксированное количество ядер для каждого исполнителя. Размер стека относится к памяти исполнителя Spark и задается свойством spark.executor.memory с флагом –executor-memory. Память исполнителя обычно определяется тем, сколько памяти рабочего узла в кластере может использовать приложение [1].
Как самостоятельно разработать Spark-приложение для аналитики больших данных и задать для него максимально эффективные настройки, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark

