Обычно курсы по Spark подробно рассказывают, чем хорош этот Big Data фреймворк для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных. Но, чтобы обучение Apache Spark было максимально полезным, стоит знать и о недостатках этого многофункционального инструмента обработки больших данных. Сегодня мы рассмотрим некоторые проблемы, которые возникают при практическом использовании Спарк.
Псевдопотоковая обработка в режиме micro-batch
Apache Spark позиционируется как средство потоковой обработки данных в режиме онлайн. Однако, это не совсем верно: в отличие от, например, Kafka или Storm, Спарк разбивает непрерывный поток данных на серию микро-пакетов. Поэтому возможны некоторые временные задержки порядка секунды. Официальная документация комментирует, что это не оказывает большого влияния на приложения, поскольку в большинстве случаев аналитика больших данных выполняется не непрерывно, а с довольно большим шагом около пары минут [1]. Тем не менее, эту особенность Спарк следует учитывать, если фактор времени является критичным для проектируемого Big Data приложения. Возможно, в таком случае стоит рассмотреть альтернативы Spark, например, клиентскую библиотеку Kafka Streams или другие фреймворки потоковой обработки больших данных: Apache Storm, Flink или Samza.
Кластер Apache Spark — головоломка для администратора Big Data
В отличие от классического MapReduce, реализованном в Apache Hadoop, Spark не записывает промежуточные данные на диск, а размещает их в оперативную память. Поэтому сервера, на которых развернут Спарк, требуют большего объема RAM. Это, в свою очередь, ведет к удорожанию кластера. Повышенные требования к hardware могут немного удивлять на фоне «всеядного» Hadoop-кластера, который успешно работает на любом железе, что часто образовательные курсы Big Data позиционируют как достоинство.
Кроме того, на практике возникают ситуации, когда JVM Apache Spark, а именно Garbage Collector, занимает слишком много памяти даже при большом объеме RAM [2]. Обойти это ограничение можно с помощью оптимизации заданий Спарк и регулирования размера кучи (heap) для каждого исполнителя (executor). Также имеет смысл поиграть с настройками менеджера ресурсов YARN, если используется он, а не Mesos. В частности, параметр yarn.nodemanager.resource.memory—mb определяет максимальный суммарный объем памяти, используемой контейнерами на каждом узле, а yarn.nodemanager.resource.cpu-vcores — задает максимальное суммарное количество ядер, используемых контейнерами на каждом узле [3].
Сложности со Спарк при разработке распределенных приложений
Код распределенного приложения Apache Spark недостаточно изолирован от кода самого фреймворка. Впрочем, это же самое относится к типовым map-reduce приложениям Hadoop. Такая сильная связанность продукта и фреймворка, с помощью которого он создавался, может привести к сбоям приложения при обновлении версии Спарк или отдельных библиотек, которые использовались при разработке [4].
Еще для Spark характерна проблема SQL-инъекций – уязвимости, когда в запрос к базе данных внедряется вредоносный код. Эта уязвимость считается одним из самых распространенных способов взлома веб-приложений.
Например, код SQL-запроса по выбору из таблицы persons записи с идентификатором (id), значение которого равно 1 в Apache Spark выглядит так:
val sqlDF = spark.sql(«SELECT * FROM persons WHERE id=1»)
таким образом, подстановка параметров выполняется напрямую в коде (id=1), а не генерируется при каждом исполнении. Spark SQL не поддерживает переменные связывания (bind variable) – подстановочные символы, такие как «?», для реальных значений в SQL-выражениях, которые позволяют предотвратить атаки SQL-инъекций. Это объясняется тем, чтобы рассматривать параметр как часть SQL-запроса, а не отдельную переменную [5]. Однако, таким образом проблема подстановки параметров в SQL-запрос и замены спецсимволов ложится на плечи разработчика Spark [4].
Еще 2 проблемы для Big Data программиста: UDF на PySpark
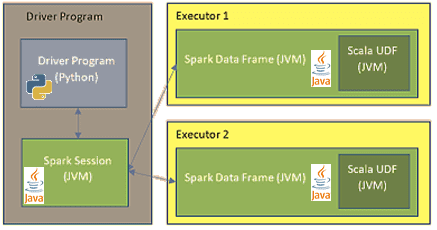
Напомним, Apache Spark позволяет разрабатывать Big Data приложения на языках Java, Scala, Python и R, предоставляя для них API-интерфейсы. Однако, если Java и Scala являются строго типизированными, то Python и R – наоборот, динамические языки. Поэтому при интерпретации кода в функции, определенной пользователем (UDF, User Defined Function) выполняется двойное преобразование данных между приложением Спарк и UDF. Это происходит из-за того, что UDF, по сути, исполняется вне виртуальной машины Java (JVM), на которой работает Спарк [4]. Например, если сравнить скорость работы PySpark и Scala Spark на практических примерах, то их быстродействие сравнимо, если PySpark действует в рамках стандартного API. Однако, при появлении UDF производительность PySpark становится ниже в 5-10 раз, чем аналогичный код на Scala. Это происходит из-за перемещения данных между процессами и тратой ресурсов на интерпретацию Python. А при вызове дополнительных функций, реализованных в модулях C++, расходы ресурсов еще больше увеличиваются, и Python работает в 10-50 раз медленнее Scala [6].
Также отметим еще одну проблему с UDF на Python в Спарк, когда некоторые компоненты библиотеки Mllib, в частности, редкие векторы (Sparse Vector), не поддерживаются API PySpark DataFrame. Однако, этот тип данных сам по себе поддерживается языком Python с помощью библиотеки NumPy для работы с большими многомерными массивами и матрицами. Обойти это ограничение можно с помощью API RDD (Resilient Distributed Dataset) – вычислительного примитива Спарк [7]. Подробнее о том, что такое RDD, Dataset и DataFrame, мы писали здесь.
Как обойти все эти и другие проблемы Apache Spark и эффективно использовать этот фреймворк для пакетной и потоковой обработки больших данных, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://spark.apache.org/faq.html
- http://zaleslaw.blogspot.com/2015/11/10-reasons-angry-about-spark.html
- http://datareview.info/article/optimizatsiya-zadaniy-apache-spark-chast-2/
- https://m.habr.com/ru/post/329838/
- http://mail-archives.apache.org/mod_mbox/spark-user/201509.mbox/%3CCACdThQ3p-m4KLsSwy9VSeARuKHfAwuQ1FmHFy2+vU=QJoE35SA@mail.gmail.com%3E
- https://habr.com/ru/company/odnoklassniki/blog/443324/
- https://issue.life/questions/55123597