Обучая дата-аналитиков и разработчиков Neo4j, сегодня разберем, что такое Aspen, как этот язык разметки переводит текст в запрос Cypher с помощью одной командной строки и каким образом это пригодится для графовой аналитики больших данных в бизнес-приложениях.
Что такое Aspen, а также как он связан с Neo4j и Cypher
Будучи написанным на Ruby в 2020 году, сегодня Aspen распространяется под лицензией MIT. Он преобразует простую описательную информацию в подробные графовые данные для использования в Neo4j, трансформируя текст в запросы Cypher. Например, Aspen преобразует это:
(Liz) [knows] (Jack)
в выражение, которое можно отправить в Neo4j:
MERGE (:Entity { name: «Liz» })-[:KNOWS]->(:Entity { name: «Jack» })
Благодаря простому синтаксису, Aspen отлично подходит для начинающих пользователей Neo4j с маленьким опытом в Cypher. В частности, этот инструмент пригодится, если нужно превратить текстовые заметки и описания в сетевую диаграмму или граф. Также можно связать эти данные с другими, например, с графами или таблицами без ML и средств обработки естественного языка (NLP) недоступны.
В файле Aspen есть раздел Discourse (дискурс), написанный вверху, и повествование, написанное внизу, всегда разделенное линией всего из четырех тире: —-. Если внутри метки не поместить какое-либо имя, Aspen присвоит ей имя Entity и предположит, что текст в круглых скобках является именем этой сущности. Когда несколько сущностей, заключенные в скобки (), являются узлами графа, следует сообщить Aspen об этом в дискурсе, следуя структуре YAML.
В разделе Narrative (нарратив) пишется описание и наблюдения в описательной форме с использованием () для имен и [] для отношений. Пример содержимого Aspen-файла может выглядеть так, где разделы дискурса и повествования разделены:
# Discourse default: label: Person ---- # Narrative (Liz) [knows] (Jack). (Jenna) [knows] (Jack). (Liz) [knows] (Jenna).
Пока Aspen поддерживает только CLI-интерфейс в виде командной строки, но в будущем разработчики планируют реализовать и наглядный GUI. CLI может просматривать файл или папку с файлами Aspen, чтобы перекомпилировать их в файл .cql или передать данные в действующую базу данных Neo4j через HTTP. Также в перспективе разработчики предполагают собрать множество рассуждений, грамматик и нарративов Aspen в один большой набор данных, который передается в базу данных. Пользовательские грамматики определяют предложения и назначают их операторам Cypher. Определив пользовательскую грамматику, можно написать простое предложение — без круглых и квадратных скобок, которое заполнит оператор Cypher. Это пригодится, когда для выражения одной концепции требуется две строки, что противоречит идее Aspen по эффективному производству данных.
Грамматика (grammar) состоит из сопоставлений (match) и шаблонов (template), которые используют язык шаблонов под названием Mustache. Mustache экранирует символы, чтобы быть безопасным для HTML, потому в шаблонах применяются тройные фигурные скобки, например:
default:
label: Person
reciprocal: knows
grammar:
-
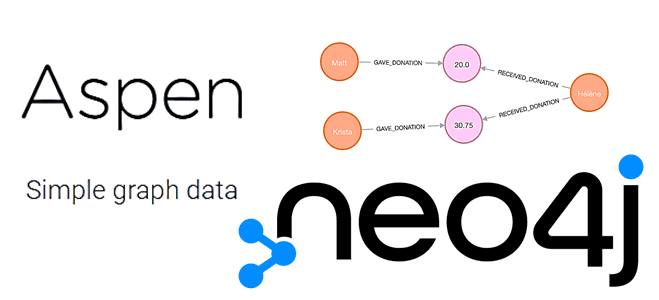
match:
- (Person a) donated $(numeric dollar_amount) to (Person b).
- (Person a) gave (Person b) $(numeric dollar_amount).
- (Person a) gave a $(numeric dollar_amount) donation to (Person b).
template:
{{{a}}}-[:GAVE_DONATION]->(:Donation { amount: {{{dollar_amount}}} })<-[:RECEIVED_DONATION]-{{{b}}}
Таким образом, пользовательские грамматики позволяют подробно описать специфические бизнес-правила.
Достоинства, недостатки и примеры использования
Как следует из краткого описания Aspen, его главным достоинством является простота и возможность быстро создать граф для Neo4j с минимальным знанием языка запросов Cypher или даже вовсе без него. Однако, Aspen не создан для полностью структурированных данных, он предназначен для частично структурированного текста, который не совсем подходит для электронной таблицы. Это означает, что пытаться создать граф для Neo4j из CSV или XLS-файла с помощью Aspen – не лучшая идея. Впрочем, это не означает запрета работать с CSV-файлами. Например, следующий скрипт парсит электронную таблицу и создает строку Aspen для каждой строки. Он устанавливает значения в Object_Type и Target_Type в качестве меток, Object и Target в качестве значений атрибутов и Verb в качестве края:
Aspen.convert.csv('src/data.csv').to_aspen do |csv_file, aspen_file|
csv_file.each do |row|
aspen_file << [
Aspen.node(row['Origin_Type'] => row['Origin']),
Aspen.edge(row['Verb'].downcase),
Aspen.node(row['Target_Type'] => row['Target']),
].join(" ")
end
end
В результате выполнения скрипта в src/data.aspen создается результирующий файл Aspen, который будет выглядеть следующим образом:
(Person: Liz) [knows] (Person: Jack)
(Person: Tracy) [is friends with] (Person: Kenneth)
(Person: Tracy) [owns] (Animal: Reef shark)
(Animal: Reef shark) [needs] (Object: A bathtub with a reef)
Тем не менее, тестирование этого инструмента показывает, что чем сложнее вариант использования, тем больше текста нужно написать. Наконец, есть некоторые ограничения в самом синтаксисе. Например, знаки подчеркивания запрещены, а имя узла нельзя изменить. Также проблематично поместить много меток в одно выражение.
Тем не менее, несмотря на некоторые недостатки и ограничения, Aspen – достаточно интересный проект, который разработчики стараются развивать. В частности, ожидается добавление защиты схемы и атрибутов, а также создание коннектора для прямой связи с экземпляром Neo4j, чтобы разрабатывать и тестировать графы для публикации данных. Наконец, в будущем пользовательский интерфейс, позволит запускать код не только локально и отказаться от ручного просмотра каталога в поисках сгенерированного файла. Как ручная аннотация графов может пригодиться на практике, читайте в нашей новой статье про выявление рецидивистов, незаконно ввозящих контрафактные товары с помощью Neo4j.
Узнайте больше подробностей про использование Neo4j и Cypher для графовой аналитики больших данных в бизнес-приложениях на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

