
Сегодня поговорим про бакетирование таблиц в Apache Spark для оптимизации производительности заданий и снижения затрат на кластер при их выполнении. Читайте далее, что такое Bucketing в Spark SQL и как это предотвращает операции перетасовки в приложениях аналитики больших данных.
Что такое Bucketing и зачем это нужно в Big Data
Бакетирование (Bucketing) — это метод в Apache Spark SQL и Hive для оптимизации производительности задачи, который разбивает данные на более управляемые части (сегменты или бакеты), чтобы ускорить последовательные чтения данных для последующих заданий. В один бакет попадают строчки таблицы, у которых совпадает значение хэш-функции, вычисленное по определенной колонке. Несмотря на похожее название, этот метод партиционирования таблиц не связан с корзинами облачных хранилищ, таких как AWS S3 или GCP GCS.
В бакетах, которые можно рассматривать как столбцы кластеризации, определяется разделение данных и предотвращается перетасовка данных (shuffle-операции). В зависимости от значения одного или нескольких столбцов, бакетированные данные распределяются по заранее определенному количеству сегментов. Это позволяет оптимизировать выполнение SQL-запросов типа JOIN, избегая перемешивания таблиц, т.к. оба соединяемых DataFrame находятся в одних и тех же разделах. Бакетирование определяет физическое расположение данных, заранее перемешивая их, чтобы избежать этого позже в процессе вычислений. В Apache Spark SQL это используется исключительно в физическом операторе FileSourceScanExec, когда он запрашивается для входного RDD и для определения разделения и упорядочения выходных данных. При большом количестве JOIN-операций такой метод существенно повышает производительность Spark-приложения за счет исключения рандомизации при JOIN-соединении или группировки по агрегату. Подобный сценарий отлично подходит для множества наборов данных с однократной записью и многократным чтением.
Таким образом, bucketing предоставляет два ключевых преимущества [1]:
- повышенная производительность запросов: во время объединений можно явно указать количество сегментов в одних и тех же бакетированных столбцах. Поскольку каждый сегмент содержит данные одинакового размера, соединения на этапе MAP при выполнении операций MapReduce работают лучше, чем таблица без сегментов. При JOIN-соединении на шаге MAP левый сегмент таблицы будет точно знать набор данных, содержащийся в правом сегменте, чтобы выполнить соединение таблицы в четко структурированном формате. О том, насколько этот прием эффективен по сравнению с другими методами выполнения запросов в Apache Spark, читайте здесь.
- Улучшенное семплирование, поскольку большие данные уже разбиты на более мелкие части.
Прежде чем использовать бакет, сначала нужно указать количество сегментов для бакетируемого столбца. Во время загрузки механизм обработки данных вычислит хэш-значение для этого столбца, на основании которого он будет находиться в одном из сегментов. Таким образом, использование бакетированной таблицы с многими разделами даст наилучшие результаты [1].
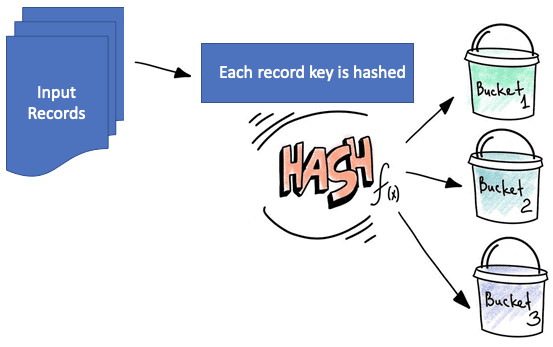
Бакетирование в Apache Spark
По умолчанию бакетирование данных в Apache Spark включено. Для изменения этого следует настроить свойство конфигурации spark.sql.sources.bucketing.enabled. Создать бакетированную таблицу можно следующим образом:
df.write\
.bucketBy(16, 'key') \
.sortBy('value') \
.saveAsTable('bucketed', format='parquet')
Команда bucketBy распределяет данные по фиксированному числу сегментов (в примере это 16) и может использоваться, когда количество уникальных значений не ограничено. Если количество уникальных значений ограничено, лучше использовать партиционирование вместо бакетирования.
Следующий код показывает пример соединения двух бакетированных таблиц.
t2 = spark.table('bucketed')
t3 = spark.table('bucketed')
# bucketed - bucketed join.
# Both sides have the same bucketing, and no shuffles are needed.
t3.join(t2, 'key').explain()
Помимо одноэтапного JOIN-соединения через сортировку слиянием, бакетирование также поддерживает быструю выборку данных. Начиная с версии 2.4, Spark SQL поддерживает сжатие бакетов для оптимальной фильтрации бакетированного столбца за счет уменьшения количества бакетированных файлов для сканирования [2].
6 достоинств и 5 недостатков бакетирования таблиц в Spark SQL
Итак, бакетирование таблиц в Apache Spark хорошо работает, когда количество уникальных значений не ограничено. К примеру, столбцы, которые часто используются в SQL-запросах и обеспечивают высокую избирательность, отлично подходят для этого метода. Партиционированные таким образом Spark-таблицы хранят метаданные о том, как они разделены на сегменты и сортируются, что помогает оптимизировать соединения, агрегаты и запросы для столбцов с разделениями [2].
Таким образом, ключевыми преимуществами метода бакетирования таблиц в Apache Spark являются следующие [1]:
- оптимизированные таблицы и датасеты;
- оптимизированные JOIN-соединения при использовании предварительно перемешанных таблиц/датасетов с разделением на сегменты;
- более эффективные запросы с предикатами для бакетированного столбца;
- оптимизация доступа к данным таблицы за счет уменьшения сканирований при запросе с условием WHERE для бакетированного столбца;
- возможность распределять данные по различным бакетам, обеспечивая оптимальный доступ к данным таблицы;
- улучшение преобразований, требующих перетасовки данных (Join, Distinct, groupBy, reduceBy).
Однако, бакетинг в Spark SQL имеет ряд ограничений [3]:
- механизмы бакетирования в Spark SQL и в Apache Hive отличаются друг от друга, поэтому переход с Hive не совсем прост.
- Bucketing в Spark SQL требует сортировки по времени чтения, что значительно снижает производительность;
- когда Spark записывает данные в бакетированную таблицу, он может генерировать десятки миллионов небольших файлов, которые не поддерживаются HDFS;
- соединения бакетов запускаются только тогда, когда их количество одинаково в двух соединяемых таблицах;
- набор ключей бакета был идентичен набору ключей JOIN-соединения или группировки.
Чтобы обойти вышеуказанные ограничения, в 2020 году в Apache Spark был добавлен ряд оптимизаций, чтобы сделать бакетирование применимым к большему количеству сценариев, а также упростить миграцию с Hive на Spark SQL [3]. Подробнее о трудностях бакетирования и способах обхода этих проблем читайте в нашей новой статье. А пример роста производительности за счет бакетирования и партиционирования смотрите в этом материале.
В заключение подчеркнем, что бакетирование пригодится в случае множественных соединений и/или преобразований, которые включают перетасовку данных с одним и тем же столбцом в бакете. Иначе эта техника может не принести ощутимой пользы [1]. О других способах оптимизации SQL-запросов в Спарк мы рассказывали здесь.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
13 мая, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Узнайте больше про особенности разработки и оптимизации распределенных приложений для аналитики больших данных с Apache Spark на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark

