
Мы уже писали про механизмы обеспечения высокой доступности в кластере Greenplum. Сегодня рассмотрим, какие инструменты и приемы помогут выявить сбои координатора и сегментов, а также как администратору кластера этой MPP-СУБД восстановить ее работоспособность. Что такое зеркалирование сегментов Greenplum Напомним, кластер Greenplum представляет собой несколько экземпляров популярной объектно-реляционной базы данных (БД)...
PL/Container для Greenplum: безопасный запуск UDF в Docker-контейнере

Как сделать запуск UDF-функций Python или R на узлах сегмента Greenplum более быстрым и безопасным с помощью Docker-контейнеров и расширения PL/Container. Что такое PL/Container и как это использовать в Greenplum Запуск пользовательского кода для базы данных всегда имеет риск нарушения информационной безопасности. Если речь идет о стеке Big Data, ущерб...
Как подключиться к Greenplum: обзор клиентов и настройка конфигураций
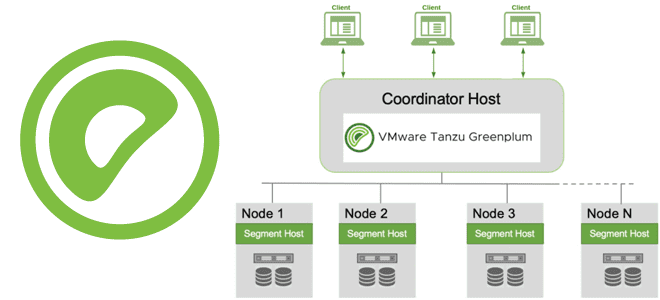
Через какие интерфейсы пользователи и клиентские приложения могут подключиться к базе данных Greenplum, как происходит подключение, какие параметры и конфигурации надо задать при этом, а также почему для этого так важна библиотека libpq. Параметры подключения к Greenplum Пользователи могут подключаться к базе данных Greenplum с помощью клиентской программы, совместимой с...
Хранение и обработка JSON-документов в Greenplum

Чем тип JSONB отличается от JSON и почему это так важно для хранения и обработки данных гибкой структуры в Greenplum. Примеры SQL-запросов к JSON-данным и особенности синтаксиса JSONPath. Чем JSONB отличается от JSON и почему это так важно? Будучи основанной на PostgreSQL, Greenplum имеет множество аналогичных возможностей, включая поддержку работы...
Генерируемые столбцы в Greenplum 7: возможности и ограничения
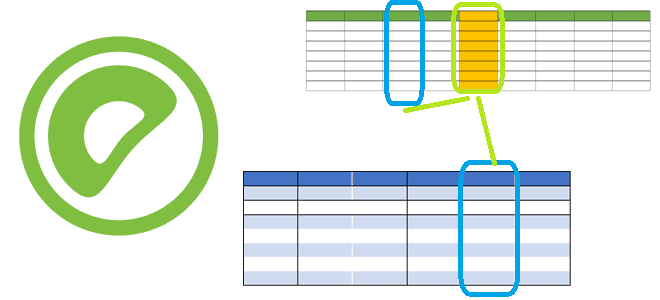
Зачем в Greenplum 7 добавлены вычисляемые (генерируемые) столбцы, как их использовать, и чем они опасны: достоинства, недостатки и ограничения этой возможности. Что такое генерируемые столбцы Поскольку Greenplum основана на PostgreSQL, эта MPP-СУБД имеет множество похожих функций. В частности, в 7-ю версию Greenplum добавлена возможность сохранения вычисляемых (генерируемых) столбцов, которые вычисляются...
Хранимые процедуры и триггеры в Greenplum
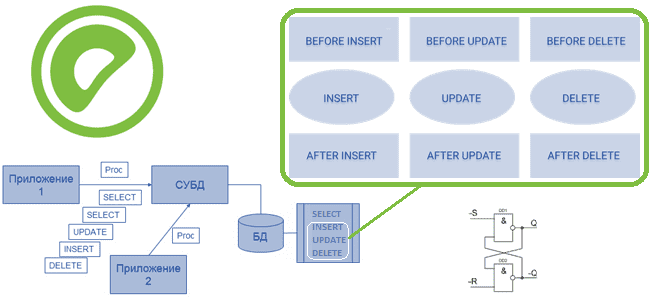
Где и как используются триггеры, чем они отличаются от хранимых процедур, как это реализуется в Greenplum. Создание, изменение и удаление триггеров и ограничения их применения в Greenplum. Что такое хранимые процедуры и триггеры Напомним, хранимые процедуры представляют собой именованные блоки SQL-команд, которые заранее откомпилированы и хранятся на сервере, чтобы ускорить...
Python для Greenplum: обработка миллионов строк внутри БД с новой библиотекой
Чего не хватает в PL/Python и зачем нужна еще одна библиотека для создания Python-скриптов обработки данных в Greenplum. Возможности API GreenplumPython и сравнение с pandas. Что такое PL/Python и как это работает в Greenplum Мы уже писали, что Greenplum изначально поддерживает Python, предоставляя PL/Python – загружаемый процедурный язык, который позволяет...
Распределенные снапсшоты в Greenplum для производительности и надежности
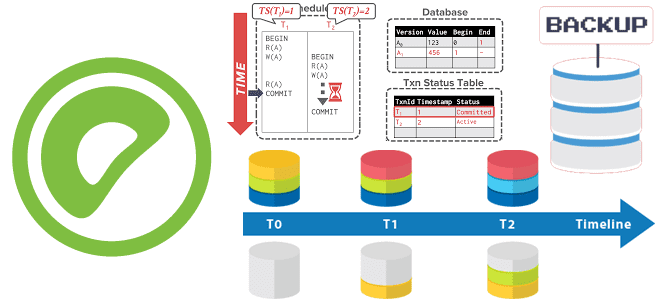
Как Greenplum расширяет MVCC-модель PostgreSQL для управления доступом к данным в многопользовательской среде, обеспечивая согласованность и изоляцию транзакций для нескольких сегментов в большом кластере. Преимущества моментальных снимков перед блокировками и их польза для резервного копирования. MVCC и транзакции в Greenplum с PostgreSQL Будучи основанной на PostgreSQL, о чем мы писали здесь,...
Графовая аналитика в Greenplum и PostgreSQL: обзор расширений и возможностей
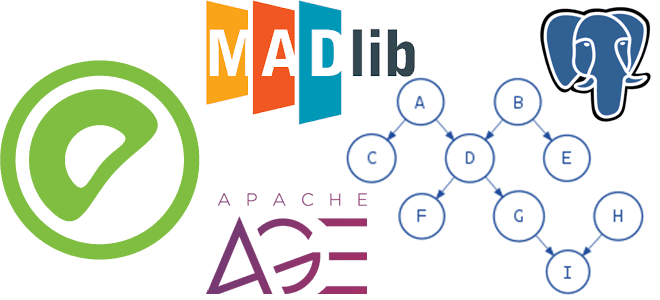
Инструменты графовых алгоритмов для аналитики больших данных в PostgreSQL и Greenplum: обзор расширений и возможностей. Знакомимся с Apache AGE и MADlib. Графовая аналитика в PostgreSQL Реляционные СУБД отлично подходят для хранения данных с четкой структурой практически в любой предметной области и предлагают широкие возможности аналитической обработки таких данных. Но иногда реляционная...
EDA-архитектура данных в DWH: моделирование и реализация
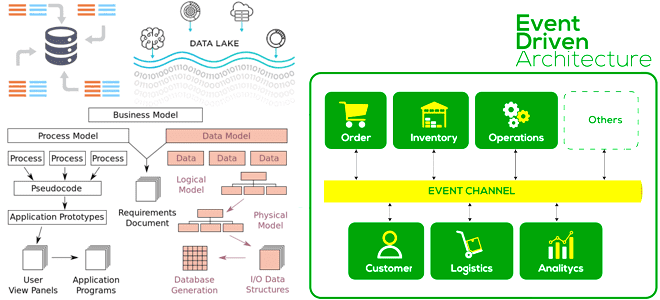
Чем схема, применяемая к данным, при чтении отличается от схемы при записи, почему она вызывает GIGO-проблему в Data Lake, и как применить принципы функциональной дата-инженерии к архитектуре данных, управляемой событиями. Схема при чтении или при записи: главное отличие NoSQL-решений от реляционных СУБД NoSQL-решения и Apache Hadoop реализуют стратегию «схема при...