
Чем хороши JSON-файлы и как с ними работать в Apache Spark и Hive: проблемы обработки вложенных структур данных и способы их решения на практических примерах. Как автоматизировать переименование некорректных названий полей во вложенных структурах данных JSON-файлов на любом количестве таблиц со множеством полей, чтобы создать таблицу в Hive Metastore и...
UDF в Apache Hive: создание, регистрация и эксплуатация

Сегодня в рамках обучения дата-аналитиков и разработчиков распределенных приложений, рассмотрим, что такое пользовательские функции в Apache Hive, как их создать и использовать. А также в чем проблема вызова UDF-функции, зарегистрированной в Hive, из Impala и при чем здесь Sentry. Простые и сложные UDF в Apache Hive Пользовательские функции в Hive...
Базовые DDL-операции в Apache Hive: основы NoSQL Big Data для начинающих

В прошлый раз мы говорили про DML-операции в Hive. Сегодня поговорим про DDL-операции в этой распределённой Big Data платформе. Также рассмотрим применение этих операций к объектам, хранящимся в этой СУБД. Читайте далее про особенности работы DDL-операции в Hive. DDL-операции в СУБД Apache Hive DDL-операции (Data Definition Language, Язык Определения Данных)...
Базовые DML-операции в Apache Hive: основы NoSQL Big Data для начинающих

В прошлый раз мы говорили про индексы в Hive. Сегодня поговорим про DML-операции в этой распределённой Big Data платформе. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про DML-операции в Hive и их особенности. DML-операции в СУБД Apache Hive DML-операции (Data Manipulation Language) -...
Дыра в Apache Log4j: опасность для Hadoop, Spark, Kafka, Neo4j и других технологий Big Data
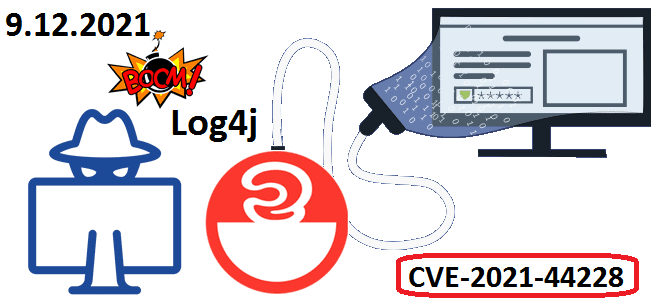
В начале декабря 2021 года мир ИТ взволновала новость о критической уязвимости CVE-2021-44228 в библиотеке Apache Log4j. Разбираемся, что это такое и чем опасно для систем хранения и аналитики больших данных на Apache Hadoop, Kafka, Spark, Elasticsearch и Neo4j. Критическая уязвимость в библиотеке Apache Log4j: чем опасна CVE-2021-44228 9 декабря...
Зачем нужна статистика таблиц Apache Hive и как ее собрать
Мы уже писали, зачем нужна статистика таблиц при оптимизации SQL-запросов на примере Greenplum. Сегодня рассмотрим, как собрать статистические данные в таблицах Apache Hive, каким образом это поможет оптимизатору запросов и какие есть способы сбора статистики в этом популярном инструменте стека SQL-on-Hadoop. Еще раз о пользе статистики для оптимизации запросов в...
Как получить доступ к данным в AWS S3 из кластера Apache Hadoop через Hive и Spark
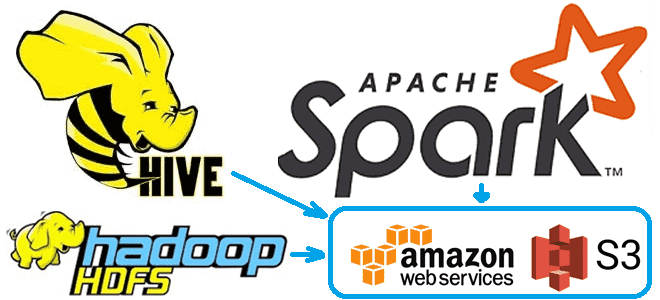
Чтобы сделать наши курсы по Apache Hadoop и компонентам этой экосистемы хранения и эффективной аналитики больших данных еще более полезными, сегодня рассмотрим, как получить данные из облачного объектного хранилища AWS S3 с помощью заданий Hive и Spark. А также заглянем внутрь конфигурационных xml-файлов Hadoop и Hive. Еще раз о разнице...
ACID-транзакции в Apache Hive: настройка, принципы работы и ограничения
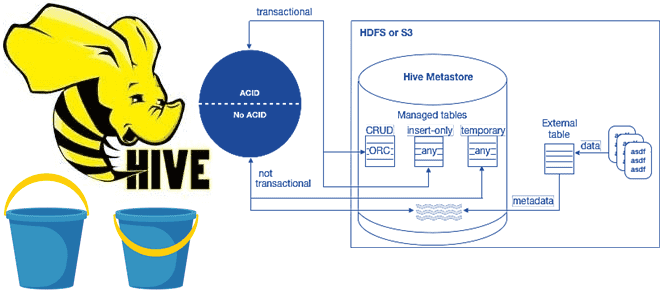
В рамках обучения аналитиков данных и дата-инженеров тонкостям работы с Apache Hive, сегодня разберем особенности ACID-транзакций в этом популярном инструменте класса SQL-on-Hadoop. Зачем и когда нужны ACID-транзакции в Apache Hive, какие параметры нужно настроить для их выполнения, при чем здесь блокировки, каковы ограничения и особенности уплотнения дельта-каталогов. Еще раз про...
Потоковая аналитика больших данных в Udemy: система отслеживания событий на Apache Hive и Kafka в AWS

Сегодня разберем кейс платформы онлайн-обучения Udemy по разработке собственной системы потоковой аналитики больших данных о событиях пользовательского поведения на Apache Kafka, Hive и сервисах Amazon. Про требования к инфраструктуре отслеживания событий и их реализацию с помощью Apache Kafka, Hive, Kubernetes, AWS S3 и EMR, а также чем AVRO лучше Protobuf....
Бакетирование vs партиционирование в Apache Hive и Spark

В этой статье рассмотрим 2 способа физической группировки данных для ускорения последующей обработки в Apache Hive и Spark: партиционирование и бакетирование. Чем они отличаются друг от друга, что между ними общего и какой рост производительности дает каждый из методов в зависимости от задач аналитики больших данных средствами Spark SQL. Еще...