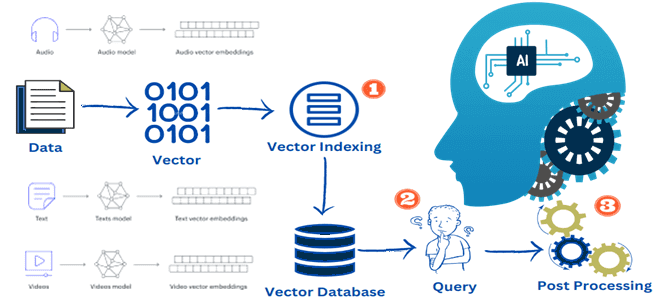
Как устроены векторные базы данных и почему они стали так популярны с распространением ИИ. Архитектура, алгоритмы, принципы работы и примеры векторных СУБД. Что такое векторная СУБД и при чем здесь ИИ Как и следует из названия, векторная база хранит данные в виде векторов. Это понятие из математики означает специализированное представление...
Новости и статьи по администрированию, аналитике, разработке и эксплуатации NOSQL технологий в Big Data: Apache HBase, Hive, Impala, Greenplum, ClickHouse и другие Not Only SQL СУБД для хранения и аналитической обработки больших данных.
3 новых графовых алгоритма в Neo4j: новинки 2023
Как включить отрицательные веса в поиск пути, выявлять центральные и периферийные кластеры на основе заданной плотности, а также делать выборки из больших графов для масштабирования машинного обучения. Знакомимся с графовыми алгоритмами, недавно добавленными в библиотеку Neo4j Graph Data Science 2.4: декомпозиция K-ядра, алгоритм кратчайшего пути Беллмана-Форда и случайное блуждание с...
Мультимодельные базы данных: мифы и реальность на примере 3-х СУБД
Как устроены по-настоящему мультимодельные базы данных, чем они отличаются от реляционных и NoSQL-СУБД, а также какова истинная природа универсального подхода к хранению и оперированию данными. Разбираемся на примере ArangoDB, OrientDB и Cosmos DB. Что такое мультимодельная СУБД и зачем она нужна Любая технология предназначена, прежде всего, для решения конкретных проблем,...
Что такое GQL и при чем здесь Cypher: новый стандарт языка запросов к графам
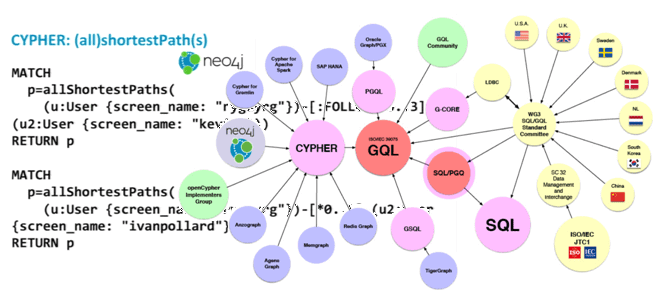
Кто и зачем создает аналог SQL для запросов к графовым базам данных, когда выйдет официальная версия стандарт и при чем здесь Cypher из Neo4j. Что такое GQL и кто его разрабатывает В рамках продвижения нашего курса по графовым алгоритмам в бизнес-приложениях мы часто рассказываем про инструменты хранения и анализа графовых...
Что такое BioCypher: возможности Neo4j для биомедицины

Зачем биомедикам понадобился свой язык описания онтологий, как эти задачи решает BioCypher и при чем здесь Neo4j: практическое приложение Data Science и графовых алгоритмов в биомедицинской сфере. Что такое BioCypher Графовые алгоритмы активно применяются в биомедицине для анализа различных биологических данных, таких как геномные, протеомные, данные о белковых взаимодействиях и...
Под капотом Neo4j: изоляция транзакций и составные базы данных

Сегодня заглянем внутрь Neo4j, чтобы разобраться с базовыми концепциями этой графовой базы данных. Какие уровни изоляции транзакций поддерживаются в Neo4j, почему одна установка по умолчанию содержит две базы данных, что такое составная БД и как с этим работать. Транзакции в Neo4j Neo4j — это популярная нативная графовая СУБД, способная управлять...
Архитектура данных для реализации паттерна Event Sourcing
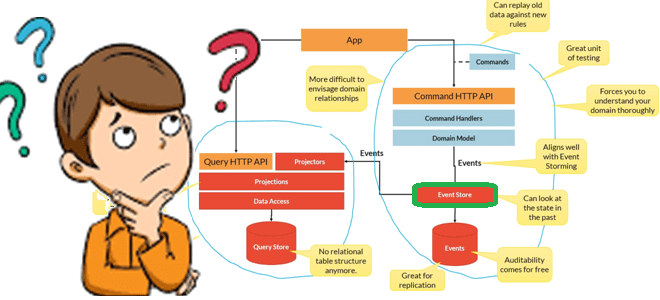
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...
Как на самом деле устроены графовые базы данных?
Что такое безиндексная смежность и как она снижает сложность алгоритмов обхода графа, позволяя быстро и эффективно запрашивать множество узлов и отношений. Разбираемся с уникальными принципами работы графовых баз данных на примере Neo4j. Архитектура и принципы работы графовых баз данных Несмотря на стремление разработчиков современных СУБД к унификации их решений, первичная...
Кто кому заплатил: пример поиска банковских транзакций в Neo4j
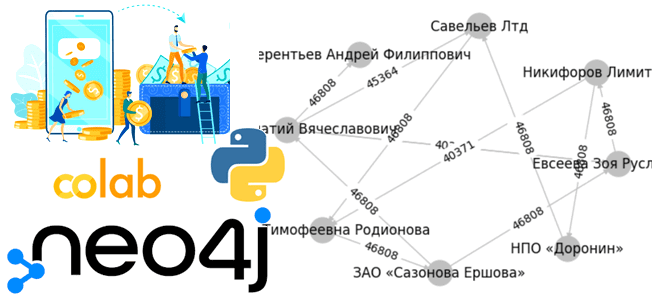
Чтобы показать еще один вариант использования графовой базы данных Neo4j, сегодня реализуем небольшое Python-приложение, которое генерирует граф знаний в облачной платформе Aura DB. Ищем финансовые переводы между компаниями и физическими лицами, считаем общую сумму и визуализируем найденные транзакции с помощью библиотеки Networkx. Python-приложение для работы с Neo4j в AuraDB Как...
В помощь дата-инженеру: как организовать конвейер инкрементной загрузки данных
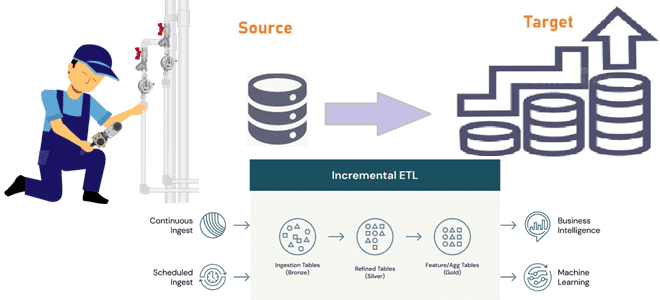
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...