
Чтобы добавить в наши практические курсы по Apache Spark еще больше приемов, полезных для дата-инженеров и разработчиков, сегодня рассмотрим, как упаковать PySpark-приложение, используя нативные Python-функции и сторонние решения. Отличия Virtualenv от PEX и Conda. 4 способа упаковать PySpark-приложение для запуска в кластере Apache Spark Разработчики распределенных приложений знают, что недостаточно...
Информационно-аналитические статьи и новости о технологиях анализа и хранения Больших Данных (Big Data), машинного обучения (Machine Learning), администрирования кластеров (Hadoop, Kafka, Spark, AirFlow), а также реальные истории и лучшие практики их прикладного использования в российских и зарубежных компаниях
3 способа совместного использования DAG-файлов в Apache AirFlow на Kubernetes
В этой статье для обучения дата-инженеров и администраторов кластера разберем способы организации совместного использования DAG-файлов при развертывании Apache AirFlow в Kubernetes. Чем хорош вариант с общими томами и почему от него лучше отказаться в пользу Git. Как организовать обмен DAG-файлами в Apache AirFlow на Kubernetes Развертывание Apache AirFlow в кластере...
Окна и водяные знаки: потоковая обработка данных с Apache Flink
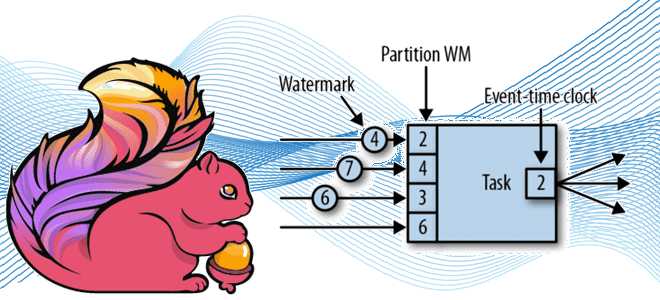
Продолжая разговор про оконные операции в Apache Flink для потоковой аналитики больших данных, сегодня рассмотрим, как это связано с другим важным концептом потоковой обработки событий – водяным знаком. Что такое Watermark и каковы стратегии его генерации в Apache Flink: самое главное для дата-инженера. Потоковая синхронизация данных c SQL для Flink...
Тонкости MERGE-запроса в Neo4j
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем особенности работы оператора MERGE во встроенном SQL-подобном языке запросов Cypher популярной NoSQL-СУБД Neo4j. Чем он отличается от запросов CREATE и MATCH, а также когда этот оператор более всего полезен. Как работает MERGE-запрос в Neo4j Data Scientist’ы и аналитики данных знают,...
Разделение репозиториев и настройка доступности: советы администратору Apache NiFi

Мы часто делимся полезными лайфхаками и лучшими практиками администрирования и эксплуатации технологий Big Data. Сегодня специально для обучения дата-инженеров рассмотрим, как лучше настроить репозитории Apache NiFi и параметры кластера, чтобы повысить производительность и надежность этого популярного ETL-маршрутизатора потока данных. 4 репозитория Apache NiFi Репозиторий потоковых файлов содержит информацию обо всех...
Не просто бургеры: архитектура данных в McDonald’s с Apache Kafka
Сегодня заглянем под капот ИТ-инфраструктуры самой знаменитой франшизы быстрого питания. Как устроена унифицированная платформа потоковой обработки событий в McDonald’s на базе облачного полностью управляемого сервиса Apache Kafka в AWS и что гарантирует высокую доступность и надежность решения. Архитектурный дизайн Архитектуры, основанные на событиях, обеспечивают гибкость интеграции, масштабируемость и некоторые возможности...
Инструментарий MLOps c MLflow и DVC: versus или вместе?
Продолжая разбираться с популярными MLOps-инструментами, сегодня рассмотрим, как MLflow реализует управление версиями модели и данных, а также чем это отличается от DVC. Преимущества и недостатки популярных MLOps-инструментов с возможностями их совместного использования. Плюсы и минусы MLflow для MLOps-инженера Концепция MLOps, направленная на сокращение разрыва между различными специалистами, участвующими в процессах...
Безопасная архитектура LakeHouse с Apache Kafka, управляемая метаданными

Сегодня рассмотрим пример построения гибридной архитектуры LakeHouse c Apache Kafka и Snowflake, которая гарантирует высокую масштабируемость и обеспечивает безопасность данных от несанкционированного доступа с помощью маскирования. От пакетного озера данных на AWS S3 к потоковому LakeHouse Будучи высоконадежной распределенной платформой потоковой передачи событий, Apache Kafka часто используется для обработки потока...
ETL с Apache Spark в озере данных на MinIO
При том, что большинство современных озер данных представляют собой облачные объектные хранилища типа AWS S3, многие предприятия хранят данные в собственном кластере HDFS или даже MinIO. Поэтому сегодня специально для обучения дата-инженеров и ИТ-архитекторов рассмотрим, что представляет собой это хранилище и насколько хорошо с ним взаимодействует Apache Spark. Что такое...
Быстрая индексация данных в HDFS, Hadoop и Spark с библиотекой Dione от PayPal
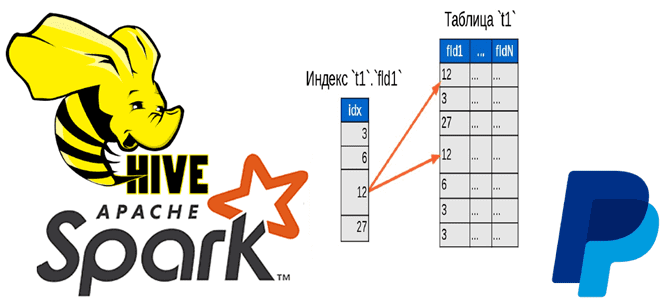
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро. Трудности бакетирования в Hive и Spark Вычислительный движок Apache Spark отлично...