Продвигая наши курсы по Apache Spark для разработчиков, сегодня рассмотрим пользовательские функции и особенности работы с ними в API SQL-модуле этого фреймворка. Читайте далее про идемпотентность UDF-функций и их влияние на распределение данных в кластере Apache Spark. Как устроены UDF в Apache Spark: краткий ликбез Пользовательские функции (User Defined Functions,...
Особенности оконных функций и кэширования датафреймов в Apache Spark SQL
В рамках обучения разработчиков Apache Spark, сегодня рассмотрим еще несколько интересных особенностей этого фреймворка, ограничивающих его типовые возможности и на PySpark-примерах разберем, как с этим бороться. Читайте далее, что такое оконные функции и зачем они нужны, как сортировка влияет на фрейм окна в Spark SQL и чем опасны действия над...
Еще 3 причуды API DataFrame в Apache Spark, о которых вы не знали
Чтобы сделать наши курсы по Apache Spark еще более полезными, мы рассказываем о неочевидных тонкостях этого фреймворка, знание которых позволит разработчику распределенных приложений использовать возможности этой технологии более эффективно. Сегодня на практических примерах PySpark в API DataFrame рассмотрим разницу между функциями сортировки массивов и особенности объединения контенкации, а также разберемся...
Преобразования vs действия: под капотом операций Apache Spark
Продолжая разговор про вычислительные операции над датафреймами в Apache Spark, сегодня рассмотрим, какие преобразования (transformations) и действия (actions) чаще всего используются при разработке распределенных приложений и аналитике больших данных. Читайте далее, про виды столбцовых преобразования и отличия действия collect() от take(). Преобразования в Apache Spark: виды и особенности реализации Напомним,...
Как быстрее обработать массив в Apache Spark 3.1: сравнение 9 разных методов
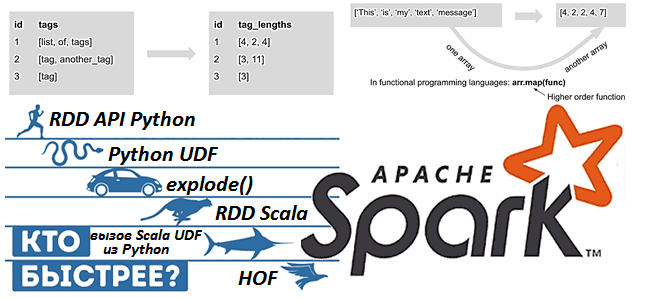
Apache Spark предоставляет для разработчика распределенных приложений множество возможностей, позволяя достигать одной целей разными способами. Чтобы проиллюстрировать это, сегодня рассмотрим бенчмаркинговое сравнение 9 методов обработки массивов в Spark 3.1, обращая внимание на их производительность и особенности использования. Также разберем важные для обучения разработчиков Spark темы про отличия преобразований от действий...
Кейс потоковой аналитики больших данных с Apache Kafka, Spark (Flink) и BI-системами

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...
Не только AirFlow: как упростить тестирование и отладку Big Data конвейеров из Spark-приложений с Dagster

Apache Spark + AirFlow – известная каждому дата-инженеру комбинация технологий Big Data для запуска сложных конвейеров обработки данных. Но совместное использование этих фреймворков ограничено недостатками AirFlow, часть из которых можно обойти с помощью Apache Livy. Однако эксплуатация AirFlow менее удобна, чем Dagster. Поэтому сегодня рассмотрим, как этот альтернативный оркестратор данных...
Как избавиться от перекосов в Apache Spark: coalesce vs repartition
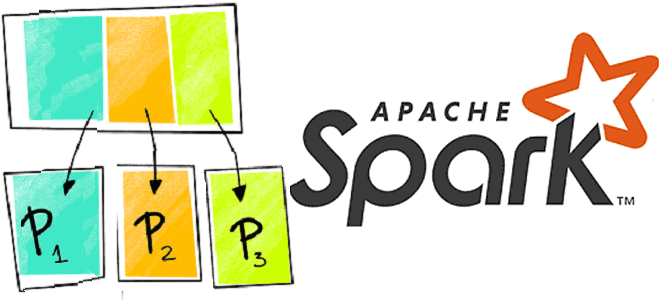
Чтобы сделать обучение разработчиков Apache Spark, дата-аналитиков и инженеров Big Data еще более наглядным, сегодня рассмотрим проблему JOIN-соединений при неравномерном распределении данных по узлам кластера и способы ее решения. Читайте далее, как избавиться от перекосов и ускорить выполнение SQL-запросов в Spark-приложениях. Перекосы данных в Apache Spark: что это и чем...
Real-time аналитика больших данных о сетевом трафике с Apache Kafka и Spark

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...
Что такое Apache Sedona или GeoSpark: Spark-фреймворк для обработки пространственных геоданных
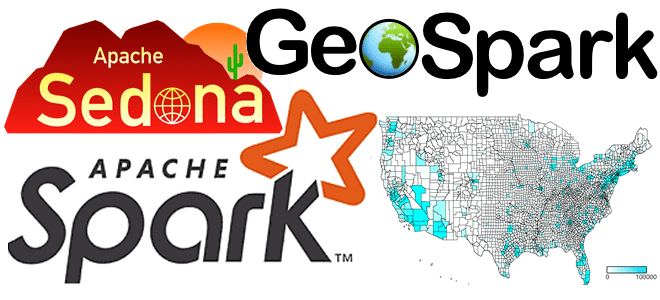
Сегодня поговорим про обработку геопространственных данных с Apache Spark и рассмотрим, что такое Apache Sedona, как этот фреймворк связан с GeoSpark, какие форматы и структуры данных он поддерживает. Читайте далее про пространственные RDD, Spatial SQL-запросы и построение конвейеров обработки геоданных в облачных сервисах Amazon. Как обработать геопространственные данные в...