Что такое барьерный режим выполнения в Apache Spark, чем он отличается от вычислительной модели MapReduce, как связан с глубоким машинным обучением и где используется на практике. Что такое барьерный режим выполнения в Apache Spark Способ выполнения заданий Spark определяется режимом выполнения приложения, заданным на уровне фреймворка. На платформе. Именно от...
Все успешно: файл _SUCCESS в рабочих процессах Apache Spark
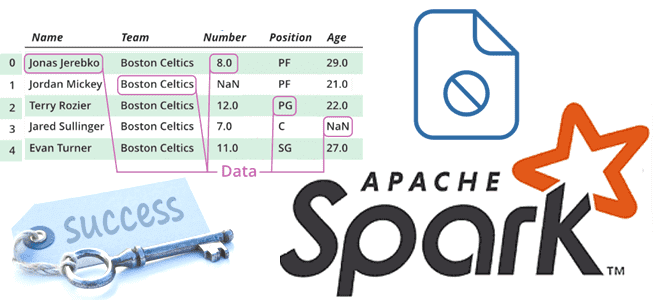
Когда и зачем Spark-приложение создает файл _SUCCESS, почему в нем нет данных, как его использовать, можно ли обойтись без него и как это сделать. Пример запуска PySpark-приложения в Google Colab. Когда и зачем Spark-приложение создает файл _SUCCESS В Apache Spark при выполнении операций записи с использованием таких методов, как saveAsTextFile(),...
Отметки времени событий для безопасности архитектуры данных Lakehouse
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...
Управление зависимостями Python в кластере со Spark Connect

Как управлять средой PySpark-приложения в распределенной вычислительной среде: проблемы зависимостей Python в кластере и способы их решения с помощью сеансов Spark Connect в версии 3.5.0. Управление зависимостями в Python и PySpark Каждый Python-разработчик хотя бы раз сталкивался с проблемой несовместимости пакетов. Эта ситуация называется ад зависимостей (dependency hell), когда вновь...
Потоковая публикация данных в REST API с Apache Spark Streaming
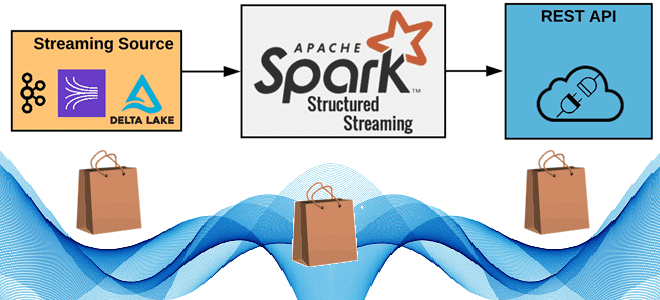
Как реализовать потоковую публикацию данных из приложения Apache Spark Structured Streaming во внешний REST API, используя метод foreachBatch(), зачем перераспределять датафрейм перед его упаковкой в полезную нагрузку HTTP-запроса, от чего зависит число вызовов, и какие приемы помогут избежать сбоев из-за ошибок. 6 шагов потоковой публикации данных в REST API с...
Эскизы данных в Apache Spark с библиотекой DataSketches

С версии 3.5.0Apache Spark поддерживает Datasketches – программную библиотеку стохастических потоковых алгоритмов. Разбираемся, что это такое, и при чем здесь алгоритм HyperLogLog. Что такое Apache Datasketches и зачем это нужно В аналитике больших данных часто возникают проблемные запросы, которые не масштабируются, поскольку требуют огромных вычислительных ресурсов и времени для получения...
Контрольные точки в Apache Spark Streaming
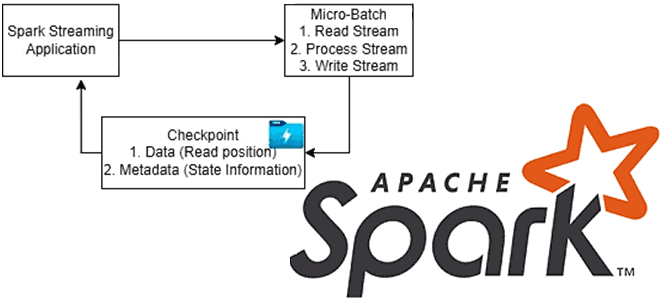
Чтобы обеспечить отказоустойчивость потоковых приложений, Apache Spark использует механизм контрольных точек. Какие они бывают, когда их включать и как настроить для эффективной работы. Что такое checkpoint в Apache Spark и зачем он нужен Чтобы приложение потоковой передачи было устойчиво к сбоям по внешним причинам, например, отказ JVM, Spark Streaming сохраняет...
Гибкая кластеризация: новая технология управления данными в Delta Lake от Databricks

Зачем разделять таблицы в озере данных, что не так с Hive-разделением и Z-упорядочение в Delta Lake и как работает жидкая кластеризация (Liquid Clustering) – новая стратегия оптимизации размещения данных от Databricks. Что не так с Hive-разделением и Z-упорядочение таблиц в Delta Lake В озере данных физическое расположение данных может оказать...
API Pandas в Apache Spark: возможности и опасности

Каждому специалисту по Data Science и инженеру данных знакома Python-библиотека pandas. Однако, для работы с большими данными она не очень подходит из-за высокого потребления памяти. Тем не менее, отказаться от старых привычек сложно. Поэтому разбираемся, зачем использовать API Pandas в Apache Spark и как это сделать наиболее эффективно. Чем отличается...
Почему производительность Apache Flink выше Spark: 5 главных причин

Из-за чего приложения Flink работают быстрее Spark: разница в моделях обработки данных, управлении памятью, методах оптимизации, дизайне API и личный опыт использования. Apache Flink vs Spark: сходства и отличия Apache Spark и Flink считаются наиболее популярными фреймворками разработки распределенных приложений в области Big Data. Они достаточно похожи, что мы ранее...