 1428
1428 Apache Hive — это SQL интерфейс доступа к данным для платформы Apache Hadoop. Hive позволяет выполнять запросы, агрегировать и анализировать данные используя SQL синтаксис. Для данных в файловой системе HDFS используется схема доступа на чтение, позволяющая обращаться с данными, как с обыкновенной таблицей или реляционной СУБД. Запросы HiveQL транслируются в Java-код заданий MapReduce.
Запросы Hive создаются на языке запросов HiveQL, который основан на языке SQL, но не имеет полной поддержки стандарта SQL-92. Однако, этот язык позволяет программистам использовать их собственные запросы, когда неудобно или неэффективно использовать возможности HiveQL. HiveQL может быть расширен с помощью пользовательских скалярных функций (UDF), агрегаций (UDAF кодов), и табличных функций (UDTF).
Архитектура HIVE:
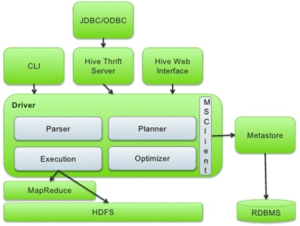
| Название компонента | Описание |
|
UI Пользовательский интерфейс |
Позволяет выполнять запросы и команды в Hive:
|
|
Meta Store (Хранилище мета-данных) |
Хранит метаданные для таблиц Hive — схему на чтение (schema-on-read) , расположение, информацию о столбцах в таблице, типы данных, ACL и тд. |
|
Hive QL Process Engine (процессор HiveQL) |
Вместо написания программ MapReduce на Java мы можем написать запрос на HiveQL для дальнейшей компиляции и исполнения задания MapReduce |
| Execution Engine (Механизм выполнения) | Составной часть процесса HiveQL Engine и MapReduce является механизм выполнения Hive. Механизм выполнения обрабатывает запрос и генерирует план задач MapReduce. |
| HDFS или HBASE | Распределенная файловая система Hadoop или HBASE — это методы хранения данных в файловой системе |
Подробнее об Apache Hive читайте в наших следующих статьях:
- Hive и Impala: коллеги или конкуренты – обзор SQL-инструментов для Apache Hadoop
- Hive vs Impala: сходства и различия SQL-инструментов для Apache Hadoop
- Что такое HiveQL: SQL для Big Data в Apache Hadoop — как работают Hive и Impala
- Как защитить Big Data в Hive и Impala: проблема безопасности в SQL-on-Hadoop