
Machine learning - множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить задачу не прямым способом, а на основе поиска закономерностей в разнообразных входных данных. Что такое Machine Learning Общий термин «Machine Learning» или «машинное обучение» обозначает множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить...
MapR

MapR Convergent Data Platform (MapRCDP) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит Apache Software Foundation, а также средств собственной разработки американской компании MapR для больших данных (Big Data) и машинного обучения (Machine Learning) [1]. Существует три версии MapRCDP: Community Edition (M3) - бесплатная версия сообщества; Enterprise Edition...
MapReduce
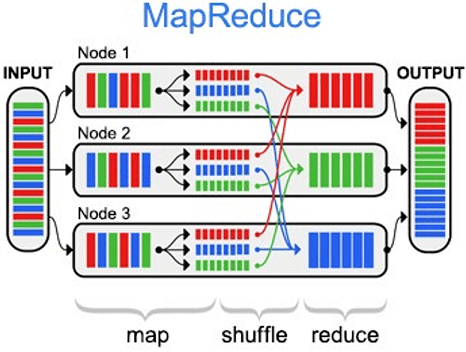
MapReduce – это модель распределённых вычислений от компании Google, используемая в технологиях Big Data для параллельных вычислений над очень большими (до нескольких петабайт) наборами данных в компьютерных кластерах, и фреймворк для вычисления распределенных задач на узлах (node) кластера [1]. Назначение и области применения MapReduce можно по праву назвать главной технологией...
Mirror Maker

Mirror Maker - это инструмент Apache Kafka, предназначенный для реализации зеркального копирования данных внутри брокера. Зеркальное копирование в Kafka подразумевает доступ к записям из разделов основного кластера с целью формирования локальной копии на дополнительном (целевом) кластере. Mirror Maker представляет собой набор потребителей, объединенных в одну группу, которые считывают данные из...
MongoDB

MongoDB - это документно-ориентированная (хранящая иерархические структуры данных в виде объектов, содержащих пары ключ/значение) система управления базами данных (СУБД), которая использует формат JSON (JavaScript Object Notation) для описания структуры хранящихся в ней объектов (документов).