Segmentation image – технология, связанная с компьютерным зрением (computer vision) и обработкой изображений, заключающаяся в обнаружении объектов определенных классов на цифровых изображениях и видео. Причем, обнаружение объектов заключается в определении класса (раскраска) каждого пикселя на цифровом изображении или на каждом кадре видеопотока. Пример кода вы можете посмотреть на GitHub MachineLearningIsEasy...
SEMMA
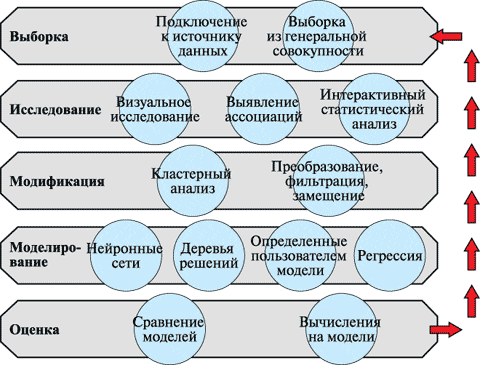
SEMMA (аббревиатура от английских слов Sample, Explore, Modify, Model и Assess) – общая методология и последовательность шагов интеллектуального анализа данных (Data Mining), предложенная американской компанией SAS, одним из крупнейших производителей программного обеспечения для статистики и бизнес-аналитики, для своих продуктов [1]. Зачем нужен стандарт SEMMA В отличие от другого широко используемого...
Sequence
Sequence File (файл последовательностей) – это двоичный формат для хранения Big Data в виде сериализованных пар ключ/значение в экосистеме Apache Hadoop, позволяющий разбивать файл на участки (порции) при сжатии. Это обеспечивает параллелизм при выполнении задач MapReduce, т.к. разные порции одного файла могут быть распакованы и использованы независимо друг от друга...