Sequence File (файл последовательностей) – это двоичный формат для хранения Big Data в виде сериализованных пар ключ/значение в экосистеме Apache Hadoop, позволяющий разбивать файл на участки (порции) при сжатии. Это обеспечивает параллелизм при выполнении задач MapReduce, т.к. разные порции одного файла могут быть распакованы и использованы независимо друг от друга [1]. Наряду с Apache Avro, Sequence File считается линейно-ориентированным (строковым) форматом Big Data, в отличие от колоночных (столбцовых) форматов (RCFile, Apache ORC и Parquet).
Структура Sequence-файла
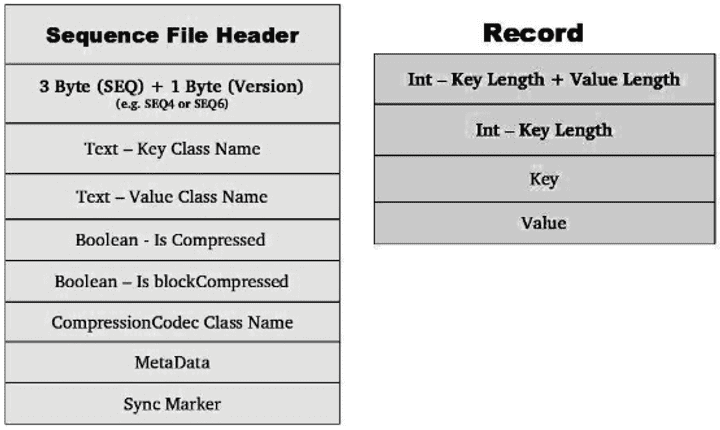
Sequence File состоит из заголовка, за которым следует одна или несколько записей.
Заголовок файла последовательности (Sequence File Header) имеет следующую структуру:
- первые 3 байта заголовка Sequence-файла занимают символы «SEQ», что идентифицирует файл последовательности. Далее следует 1 байт, представляющий фактический номер версии (например, SEQ4 или SEQ6) [2];
- далее следуют 2 текстовых поля для пары ключ/значение;
- затем 2 логических поля, которые определяют, является ли файл и блок сжатыми;
- следующее поле определяет используемый кодек сжатия;
- метаданные (MetaData) – вторичный список значений ключей, который может быть записан во время инициализации модуля записи файла последовательности [2];
- маркер синхронизации, обозначающий конец заголовка, позволяет задать размер порций для независимой распаковки и выполнять поиск случайной точки в файле, что необходимо для возможности эффективного разделения больших файлов для параллельной обработки с помощью MapReduce [1].
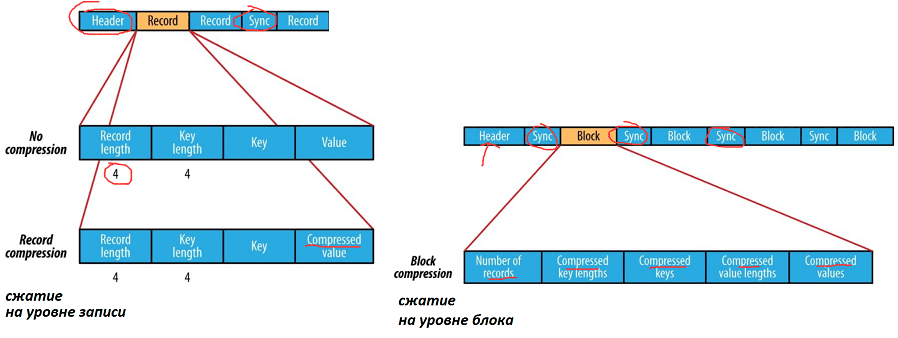
В зависимости от вида сжатия существует 3 различных формата Sequence-File [3]:
- без сжатия (No Compression) — хранение данных в порядке, соответствующем длине записи (Record length), длине ключа (Key length), длине значения (Value length), значению Key и данным (Value). Маркер синхронизации ставится примерно через каждые 100 байт.
- запись в сжатом виде (Record Compression) – каждая запись сжимается по мере ее добавления в файл, хранение данных осуществляется в порядке, соответствующем длине записи (Record length), длине ключа (Key length), значение ключа и сжатые данные (Value), а сжатый кодек хранится в заголовке;
- блок в сжатом виде (Block Compression) – сжатие выполняется, когда данные достигнут размера блока. При этом сжимается сразу нескольких записей, что позволяет воспользоваться преимуществами сходства между двумя записями и сэкономить место. Маркеры синхронизации добавляются в начало и в конец каждого блока. Минимальное значение блока задается атрибутом seqfile.compress.blocksizeset. Структура сжатого блока выглядит следующим образом:
-
- несжатое число записей в блоке (Uncompressed number of records in the block);
- сжатая длина ключа с размером блока (Compressed key-lengths block-size);
- сжатый блок с длиной ключа (Compressed key-lengths block);
- сжатые ключи с размером блока (Compressed keys block-size);
- блок со сжатыми ключами (Compressed keys block);
- блок с длиной сжатых данных (compressed value-lengths block)
- размер сжатого блока с данными (Compressed values block-size);
- сжатый блок с данными (Compressed values block).
Сжатие на уровне блока предпочтительнее чем сжатие записи, т.к. обеспечивает более компактное хранение данных. Отметим, что блок Sequence-File не связан с блоком HDFS или файловой системы [4].
Виды файлов последовательностей
Выделяют несколько разновидностей Sequence-файлов, называемые map-файлами, которые получаются путем добавления индекса и его сортировки. Индекс хранится как отдельный файл, в котором обычно лежат индексы каждой из 128 записей. Индексы ускоряют поиск по данным, т.к. могут быть загружены в память. Поскольку файлы, в которых хранятся данные, расположены в порядке, определенном ключом, записи map-файла тоже должны быть расположены по порядку, иначе возникнет исключение IOException — попытка создать уже существующий файл [3].
Производные типы map-файла:
- SetFile – для хранений последовательности ключей типа
Writable в определенном порядке; - ArrayFile – для хранения ключа – целого числа типа Writable, означающего позицию в массиве;
- BloomMapFile, оптимизированный для метода get() с использованием
динамических фильтров, которые хранятся в памяти (Bloom). Обычный метод
get() вызывается для чтения, только если значение ключа
существует.
Достоинства и недостатки Sequence-файлов Big Data
Структура файлов последовательностей обусловливает следующие преимущества этого формата:
- более компактны по сравнению с текстовыми файлами – например, 1GB Sequence-файлов с 8 блоками HDFS занимают всего около 3,6 КБ вместо 4,5 МБ для хранения 10 000 объектов в ОЗУ на узле кластера Apache Hadoop [4];
- 2 типа сжатия файлов – на уровне записи и на уровне блока;
- возможность распараллеливания задач за счет независимой распаковки и использования разных порций одного файла;
- Sequence File может выступать в качестве контейнера множества мелких файлов, что позволяет в полной мере использовать оптимизацию HDFS и MapReduce для больших объемов, избежав проблем с одновременной обработкой нескольких файлов [2].
Тем не менее, для файлов последовательностей характерны следующие недостатки:
- отсутствие многоязычной поддержки – т.к. Sequence файлы специфичны для экосистемы Apache Hadoop, взаимодействовать с ними можно лишь через Java API [2].
- формат не является человекочитаемым, что затрудняет отладку.
Где и для чего используются файлы последовательностей в Big Data
За счет своего бинарного формата Sequence-файлы очень компактны, поэтому они часто применяются в следующих целях:
- решение проблемы большого количества маленьких файлов – в Apache Hadoop ссылки на множество маленьких файлов создают большие накладные расходы памяти в узлах кластера [5];
- обработка изображений и текстовых документов, где ключом или значением является большой объект, при этом каждый документ считается отдельной записью файла последовательностей [1];
- использование в задачах MapReduce в качестве форматов ввода и вывода – внутренние временные выходные данные функции map() сохраняются в формате Sequence File [2].
Источники
- Книга «Hadoop в действии», Чак Лэм – М.: ДМК-Пресс, 2012. – 424 с., ил.
- http://hadooptutorial.info/hadoop-sequence-files-example/
- https://habr.com/ru/company/otus/blog/465069/
- http://qaru.site/questions/687495/what-is-sequence-file-in-hadoop
- https://www.edureka.co/community/775/what-is-the-use-of-sequence-file-in-hadoop